Multimodal Machine Learning: A Survey and Taxonomy
IEEE transactions on pattern analysis and machine intelligence, 2018,引用3890
多模态的五大核心挑战
表示(Representation)
目标:将异构数据(如图像、文本、音频)转换为统一或协调的表示形式。
方法:
联合表示(Joint):将多模态数据映射到同一空间(如神经网络、深度玻尔兹曼机)。
协调表示(Coordinated):不同模态独立映射,但通过相似性约束(如距离最小化、相关性最大化)协调。
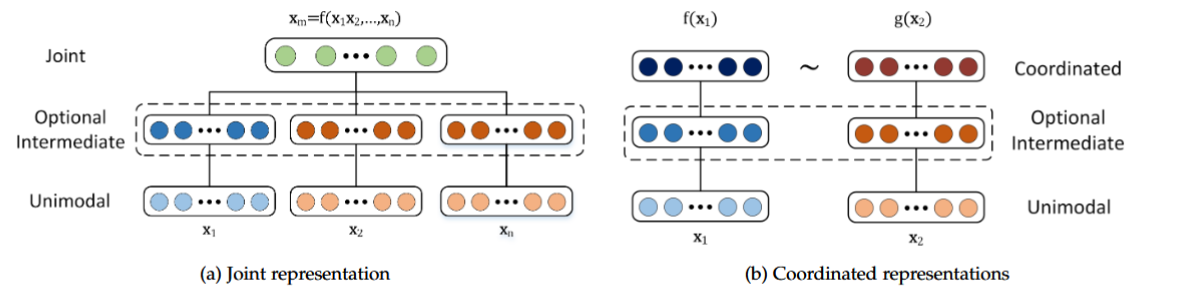
image-20250226133825056
应用:语音识别、情感分析、跨模态检索。
翻译(Translation)
目标:将一种模态的信息转换为另一种模态(如图像生成描述、文本生成图像)。
方法:
- 基于示例(Example-based):通过检索或组合现有示例生成结果。
- 生成式(Generative):使用编码器-解码器框架(如RNN、LSTM、注意力机制)生成新内容。
挑战:评估困难(如主观性、多正确答案),常用BLEU、ROUGE等指标。
对齐(Alignment)
目标:找到不同模态子元素间的对应关系(如视频帧与文本描述的对齐)。
方法:
- 显式对齐:动态时间规整(DTW)、图模型(HMM、CRF)。
- 隐式对齐:注意力机制(Attention)、神经网络隐式学习对齐。
应用:视频-文本对齐、视觉问答(VQA)。
融合(Fusion)
目标:整合多模态信息进行预测(如情感识别结合语音和面部表情)。
方法:
- 模型无关:早期融合(特征拼接)、晚期融合(决策加权)、混合融合。
- 基于模型:多核学习(MKL)、图模型(CRF)、神经网络(LSTM、多模态RNN)。
挑战:处理噪声、模态缺失、时序不一致性。
协同学习(Co-learning)
目标:利用资源丰富的模态辅助资源稀缺的模态学习。
方法:
- 并行数据:协同训练(Co-training)、迁移学习。
非并行数据:零样本学习(ZSL)、概念嵌入(Conceptual Grounding)。
- 混合数据:通过中间模态桥接(如多语言图像描述)。
应用:跨模态检索、少样本学习。