Learning Transferable Visual Models From Natural Language Supervision
29438次引用,Proceedings of the 38th International Conference on Machine Learning, PMLR 139:8748-8763, 2021.
摘要部分提到,现有的计算机视觉系统通常通过预定义的固定类别进行监督训练,限制了其泛化能力。CLIP通过从自然语言监督中学习,使用4亿个(图像,文本)对进行预训练,实现了零样本迁移到多种下游任务,效果与全监督模型相当。Contrastive Language Image Pre-training,CLIP。
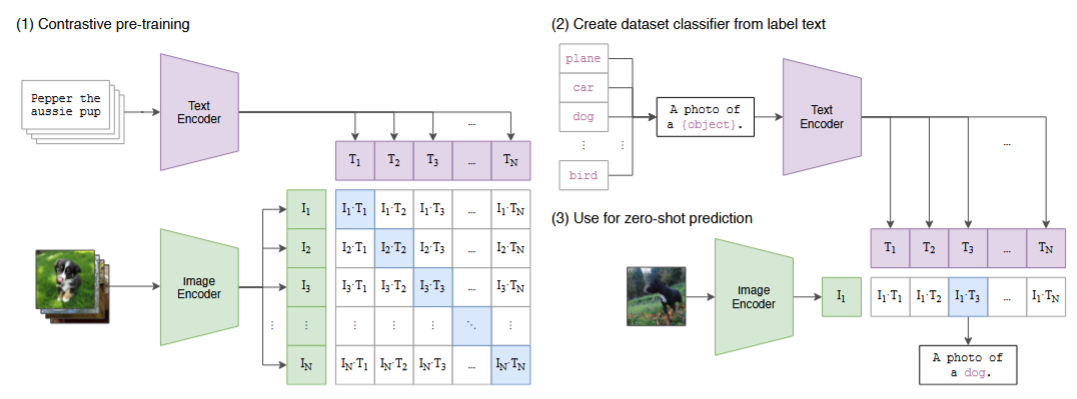
Approach
数据收集与处理
- 数据集构建:
- 从互联网抓取4亿个(图像-文本)对,构成WebImageText (WIT)数据集。
- 通过500,000个搜索词(覆盖物体、场景、动作等)确保数据多样性。
- 过滤低质量数据:移除重复样本、非英语文本、含攻击性内容的图像。
- 关键设计:
- 弱监督对齐:文本与图像的关系是弱相关(如网页图片与周围文本),而非严格对齐(如COCO的详细区域描述)。
模型架构
有一批N(image,text)pairs,预测真正匹配的图像-文本对。
训练一个image encoder和一个text encoder,最大化N个正确配对的cosine similarity,最小化\(N^2-N\)个错误配对,对相似性分数进行了symmetric cross entropy loss
| 组件 | 结构细节 |
|---|---|
| 图像编码器 | ResNet变体(如ResNet-50)或Vision Transformer(ViT,patch size 14x14) |
| 文本编码器 | Transformer(最大63M参数,12层,512隐藏层,8头注意力) |
| 特征映射 | 图像/文本特征通过线性投影层映射到共享嵌入空间(维度512或768) |
对比学习目标
损失函数:
- 对称对比损失(Symmetric Contrastive Loss): \[ \mathcal{L}_{\text{contrastive}} = -\frac{1}{2N} \left( \sum_{i=1}^N \log \frac{e^{\text{sim}(I_i, T_i)/\tau}}{\sum_{j=1}^N e^{\text{sim}(I_i, T_j)/\tau}} + \sum_{i=1}^N \log \frac{e^{\text{sim}(T_i, I_i)/\tau}}{\sum_{j=1}^N e^{\text{sim}(T_j, I_i)/\tau}} \right) \]
- 其中:
- \(\text{sim}(I, T)\):图像和文本特征的余弦相似度
- \(\tau\):可学习的温度系数(设为可学习的一个标量)
- \(\text{sim}(I, T)\):图像和文本特征的余弦相似度
Zero-Transfer
图中左侧是zero-transfer的推理部分,对感兴趣的部分进行prompt engineering,例如认为图片中有cat、dog、bird、plane,就构建一个句子A photo of a cat dog bird plane,经过text embedding,会构建一个4维向量,然后这个向量与image encoder提取得到的特征计算cosine similarity,经过一个softmax分类头,得出最后的标签。
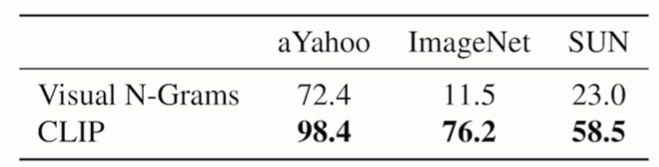
下图是CLIP和visual N-Grams的对比,CLIP没有用ImageNet中的任何一张图片进行训练。
Prompt Engineering
Issue:
- Polysemy:提示词可能具有歧义(例如boxer)。
- Describition:对图片的描述可能是一个句子。
作者使用一个模板“A photo of a {label}”,若是提前知道信息,将信息加入到prompt,对zero-shot很有用。多用一些prompt做ensemble,效果会很好。
