Flamingo: a Visual Language Model for Few-Shot Learning
发布于NeurIPS。
三大创新点:
- bridge powerful pretrained vision-only and language-only models.
- handle sequences of arbitrarily interleaved visual and textual data.
- seamlessly ingest images or videos as inputs.
模型能力
- 多模态输入处理能力
Flamingo 的核心突破是能够处理图像/视频与文本交错的多模态输入。例如:
[图片] + "这是什么动物?" → "斑马" [视频] + "发生了什么?" → "一只猫跳上桌子"
模型通过观察这些图文交错的示例,直接生成答案。
- 结合预训练视觉与语言模型 Flamingo 的架构整合了两种预训练模型:
视觉模型:负责提取图像/视频的语义特征(例如 CLIP、ViT)。 语言模型(LM):负责基于视觉特征生成文本(例如 GPT-3)。 关键设计:通过冻结预训练参数(不更新权重)并添加轻量级适配层,将两者连接,既保留预训练知识,又实现多模态交互。
- 高效处理高分辨率图像/视频 采用 Perceiver 架构,将高分辨率视觉输入压缩为固定数量的特征向量,解决了传统模型因分辨率高导致计算量爆炸的问题。
模型架构
整体框架
Flamingo 的架构基于 预训练视觉编码器 + 预训练语言模型 + 桥接模块 的三明治结构:
- 视觉编码器:采用冻结的 NFNet(F6 版本),通过对比学习预训练,提取图像/视频的时空特征。
- 语言模型:基于 Chinchilla(1.4B/7B/70B 参数)的冻结 Transformer 解码器。
- 桥接模块:包含 Perceiver Resampler 和 门控交叉注意力层,实现视觉到语言的语义映射。
Perveiver从Vision Encoder接收时空特征,输出一个定长的vision tokens,冻结的LM利用交叉注意力交错使用tokens进行next token预测任务
核心模块
Vision Encoder
- 模型选择:NFNet-F6
- 预训练方式:对比学习(CLIP风格),目标函数为图文匹配,使用two-term contrastive loss
- 关键技术
- 视频数据处理:1FPS抽帧 → 单帧独立编码 → 添加可学习时间嵌入
- 特征输出:输出2D/3D空间特征网格(例如 2048维 × 14×14),最终都拉平了
Perceiver Resampler
- 接收可变长度的feature为输入,将其转为固定长度(64)
- 处理流程
- Latent Queries:64个可学习查询向量(长度=视觉特征维度)
- Transformer Cross-Attention:查询向量与视觉特征交互
- Self-Attention:查询向量间信息聚合
Conditioning frozen language models on visual representations
Conditioninig指在visual representation之下。
下图是Interleaving new GATED XATTN-DENSE layers within a frozen pretrained LM,冻结的LLMblock前加入了一个GATED XATTN-DENSE block,使用tanh-gating是为了保证初始化时条件模型和原始语言模型有相同的结果。GATED XATTEN-DENSE将从头开始训练,与冻结的LLM交错拜访,vision信息x只用于GATED XATTN-DENSE block的训练。
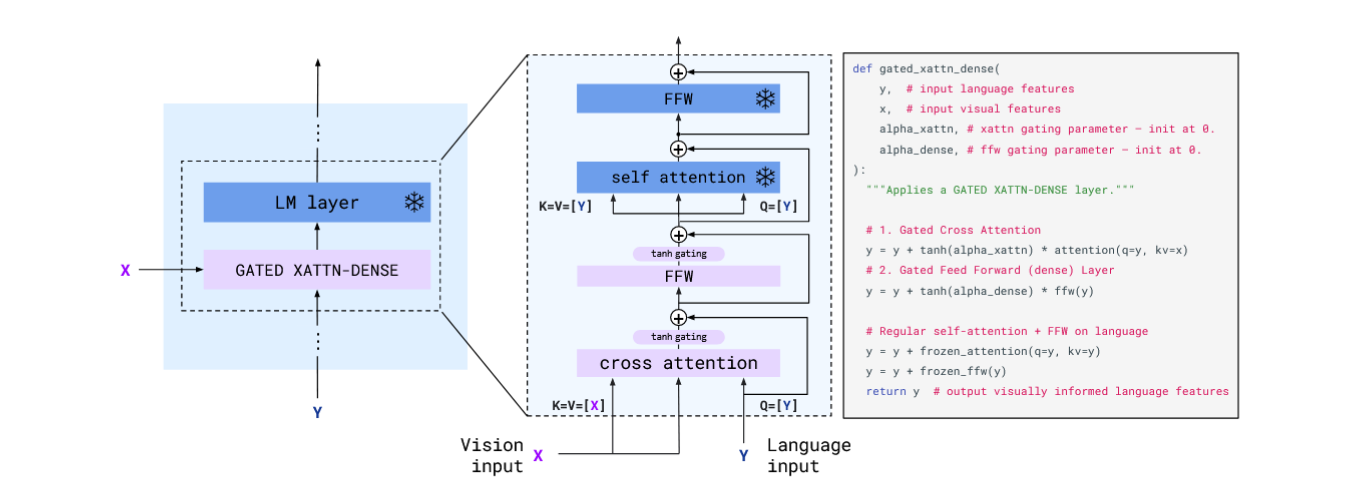
Multi-visual input support: per-image/video attention masking
掩码full text-to-image cross-attention matrix, 以便限制model在每个token能看见的visual token。
<img1> Text1 <img2> Text2如果这是输入序列,那么Text2就不能看见img1的token,必须对应。结果
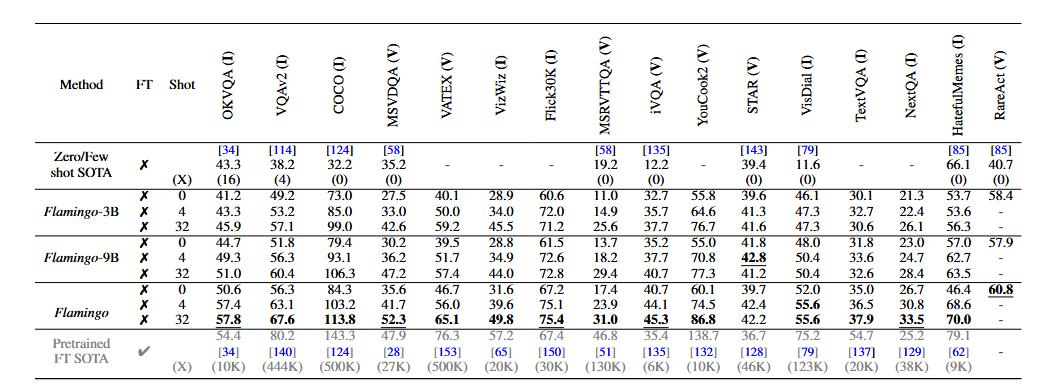
image-20250227195351479