BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
PLMR,4332
Method
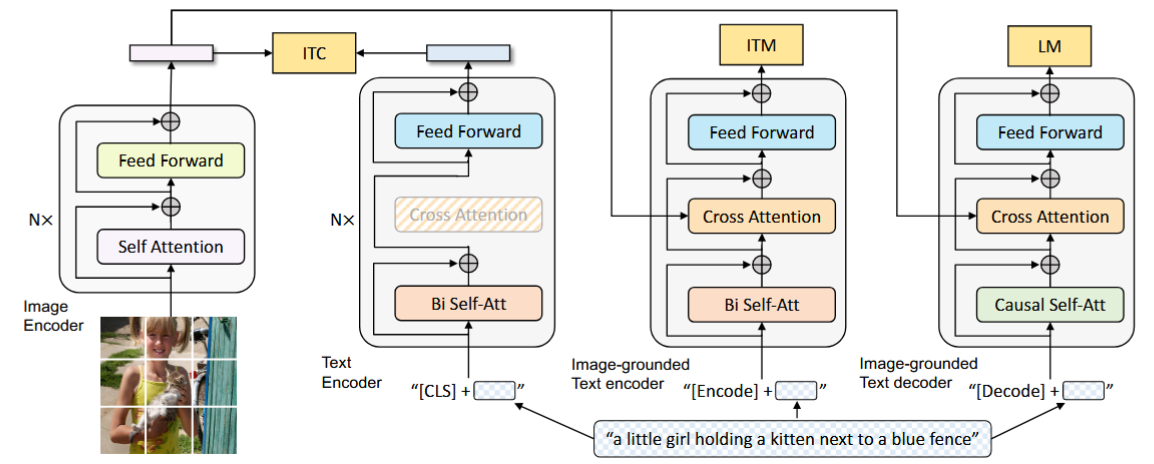
Model Architecture
Multimodal mixture of encoder-decoder (MED)
- Unimodal encoder: 图像使用ViT,文本使用Bert
- Image-grounded text encoder:通过在文本编码器的每个 transformer 块的自注意力 (SA) 层和前馈网络 (FFN) 之间插入一个额外的交叉注意力 (CA) 层来注入视觉信息。
- Image-grounded text decoder:将Image-grounded text encoder中的bidirectional self-attention layers替换为causal self-attention layers。
Pre-training Objectives
三个预训练目标,两个understanding based,一个generation based。每一对图文,需要经过一次图像encoder和三次text encoder。
Image-Text Contrastive Loss (ITC)
使用了ALBEF中的思路,用ITC加强图文对应的语义信息,并且使用动量蒸馏模型。
Image-Text Matching Loss (ITM)
同样使用了ALBEF进行ITM的思路。
Language Modeling Loss (LM)
使用了image-grounded text decoder,生成对图片的文本描述。优化了交叉熵损失,训练模型以自回归方式最大化文本的可能性。计算损失时,应用 0.1 的标签平滑。
为了提高效率,text encoder 和text decoder之间除开SA layers,权重全部共享,因为两个任务的区别主要在于SA layers。
CapFilt
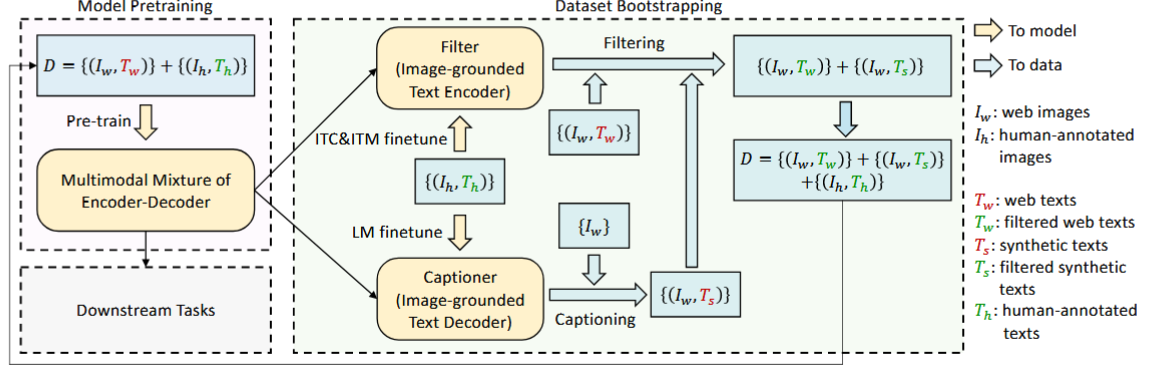
Filter和Captioner从预训练的MED中初始化,然后在COCO上微调。
Captioner是image-grounded text decoder,使用前文的LM objective微调,学习如何生成描述。Filter是一个image-grounded text encoder,使用前文的ITC和ITM去学习图文是否匹配。
Experiments and Discussions
预训练设置与数据集
| 配置项 | 参数细节 |
|---|---|
| 视觉编码器 | ViT-B/16 (224x224输入) |
| 文本编码器 | BERT-base (12层, 768隐藏维度) |
| 预训练总数据量 | 134M (12M清洗数据 + 122M噪声数据) |
| 训练硬件 | 64x NVIDIA A100 (400 GPU hours) |
核心实验结果
| 任务类型 | 评估指标 | BLIP | CLIP | ALBEF |
|---|---|---|---|---|
| 图文检索 | COCO R@1 | 76.8% | 68.3% | 72.6% |
| 视觉问答 | VQA Acc | 77.3% | - | 75.2% |
| 图像描述生成 | CIDEr | 135.2 | - | 121.8 |
消融实验分析
| 消融组件 | 图文检索R@1 | 生成CIDEr | 结论总结 |
|---|---|---|---|
| 完整模型 | 76.8% | 135.2 | 基准性能 |
| 移除CapFilt | 68.5%↓ | 120.6↓ | 数据清洗提升8.3%/14.6% |
| 仅用单模态编码器 | 71.2%↓ | - | 跨模态融合贡献5.6%↑ |
跨领域泛化表现
| 测试领域 | 数据集 | R@1 | 相对CLIP提升 |
|---|---|---|---|
| 医学影像 | COVID-Xray | 63.2% | +11.4%↑ |
| 艺术创作 | ArtEmis | 58.7% | +9.8%↑ |
| 工业质检 | PCB-Text | 51.3% | +7.6%↑ |