Self-supervised Learning
Self-supervised learning is a form of unsupervised learning. In the example below, we split the input 
Masking Input
- Use a special token of random token to masking some tokens randomly.
- minimize cross entropy of masked output and ground truth.

Next Sentence Prediction
SOP: predict the order of sentence1 and sentence2. It is more useful than next sentence prediction, perhabs because that sop is more complicate than nsp.

Bert can be a powerful baseline model.  ## GlUE
## GlUE
GLUE Score is often used to evaluate perfomerence of bert. 
How to use BERT
Case 1

Case 2

Case 3


Case 4



Pre-training a seq2seq model

 ## Trainging BERT is challenging
## Trainging BERT is challenging
Training data has more than 3 billions of words.
Why does BERT work
BERT can consider context. 

GPT Series
Predict the next token 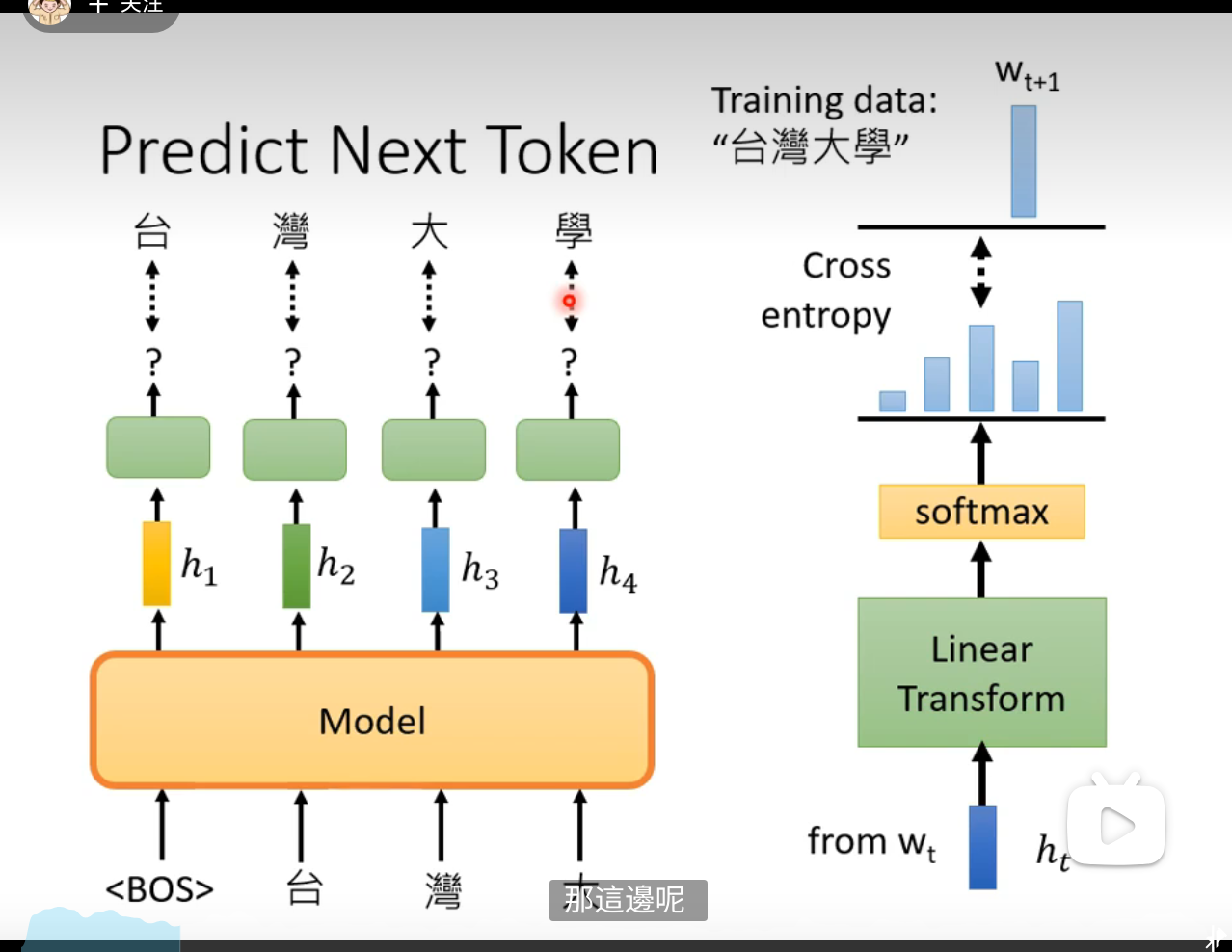
Problems and solutions of PLMs
Labeled Data Scarcity
Data-Efficient Fine-tuning
Prompt Tuning
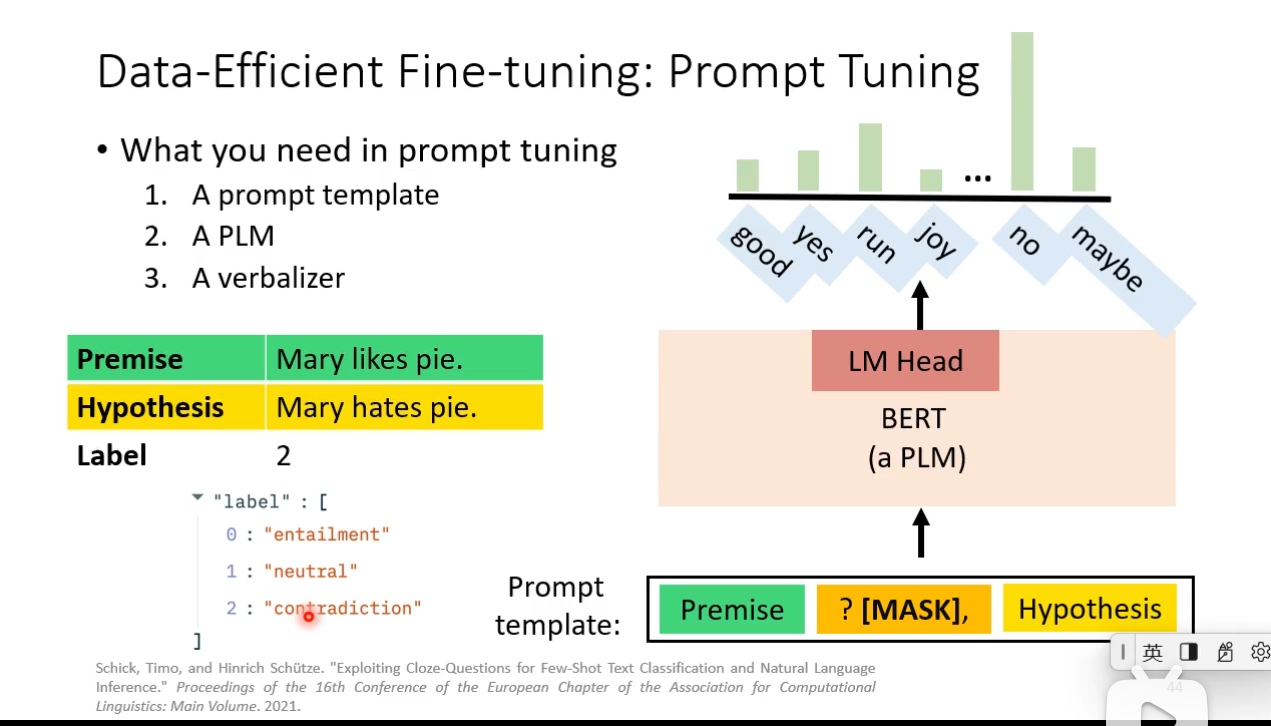
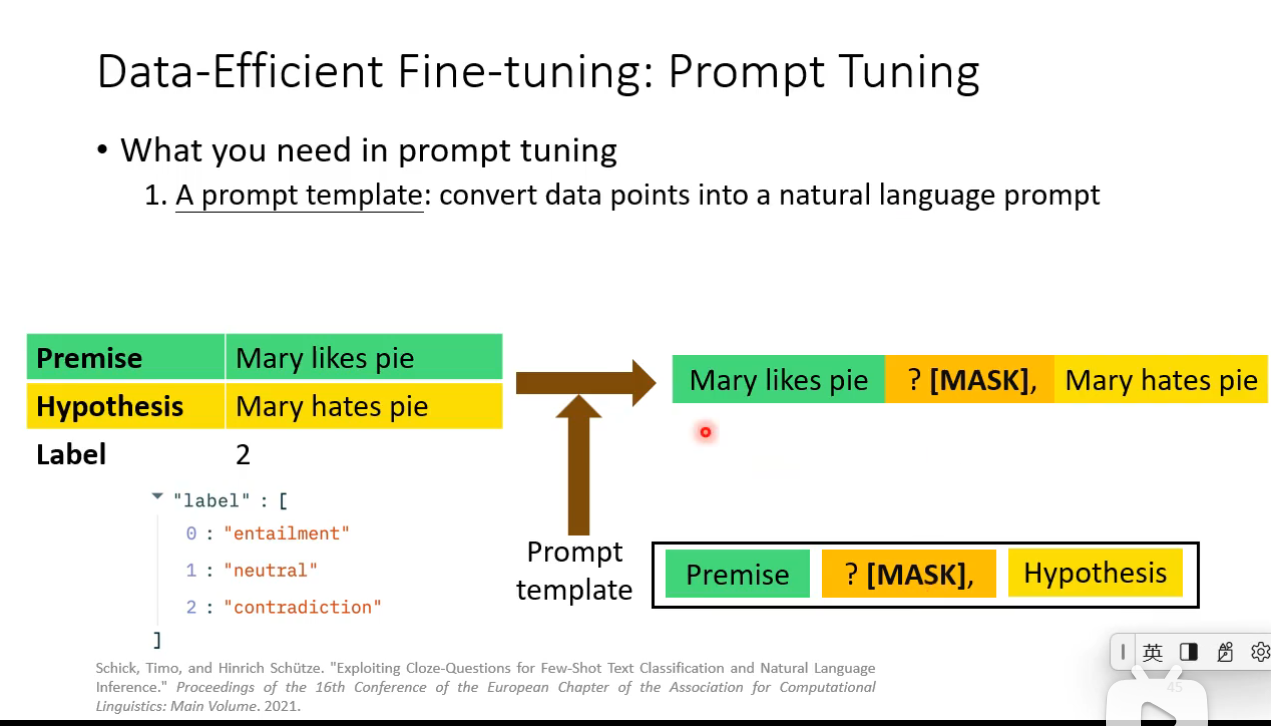
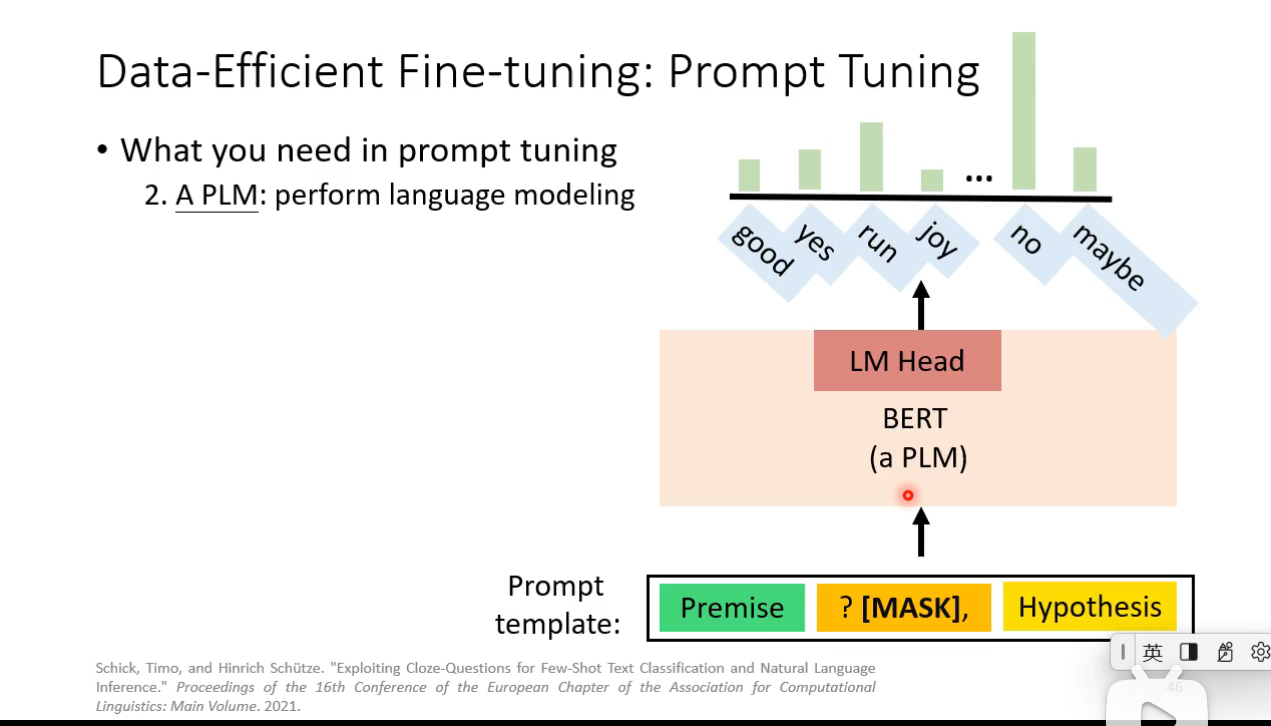
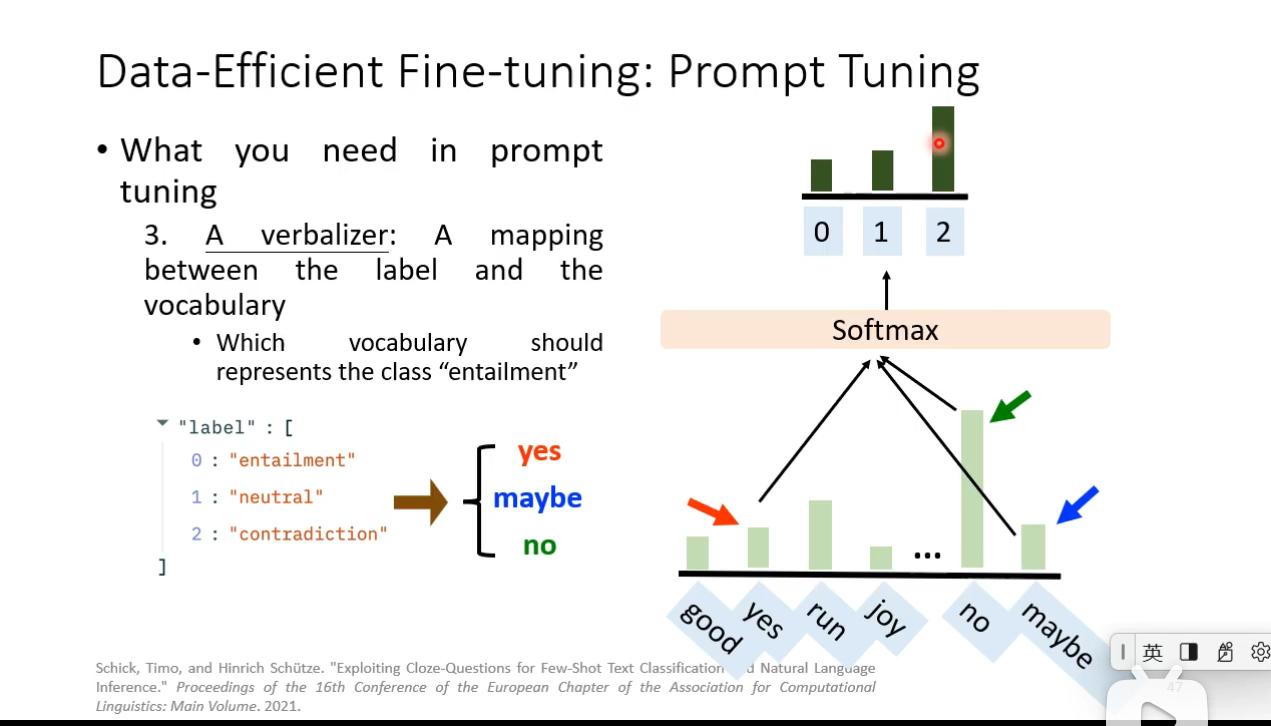
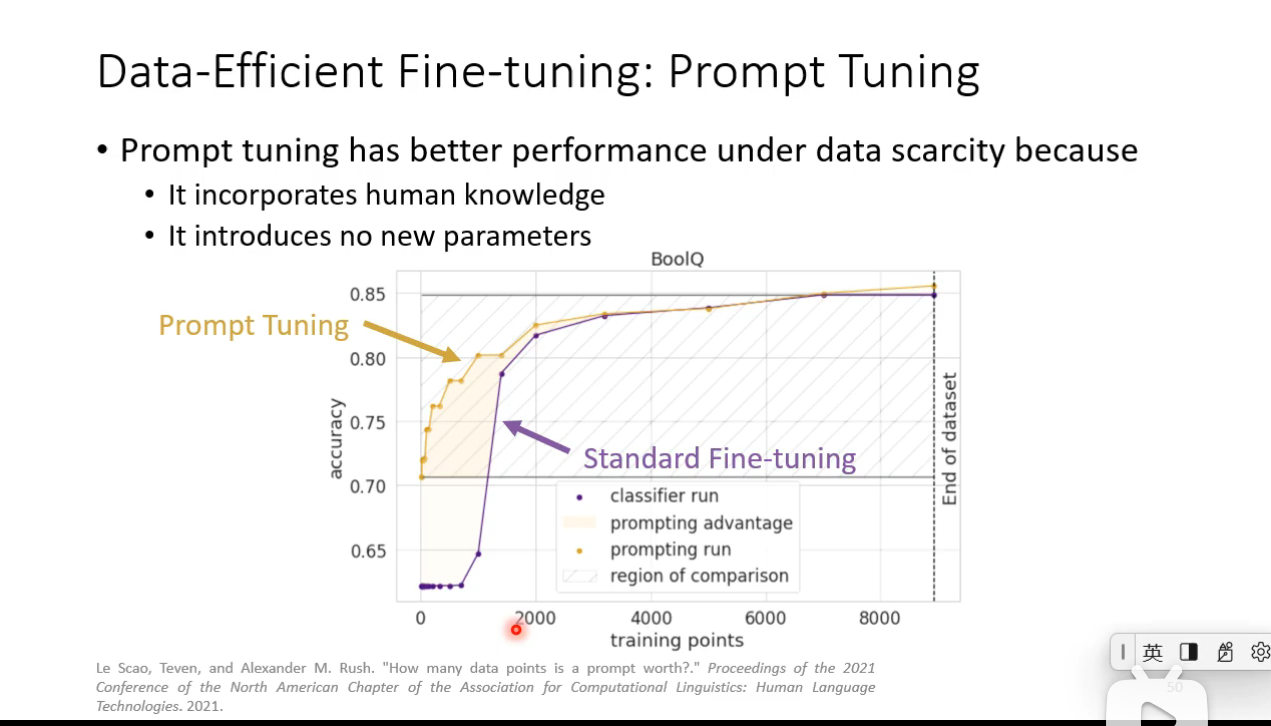
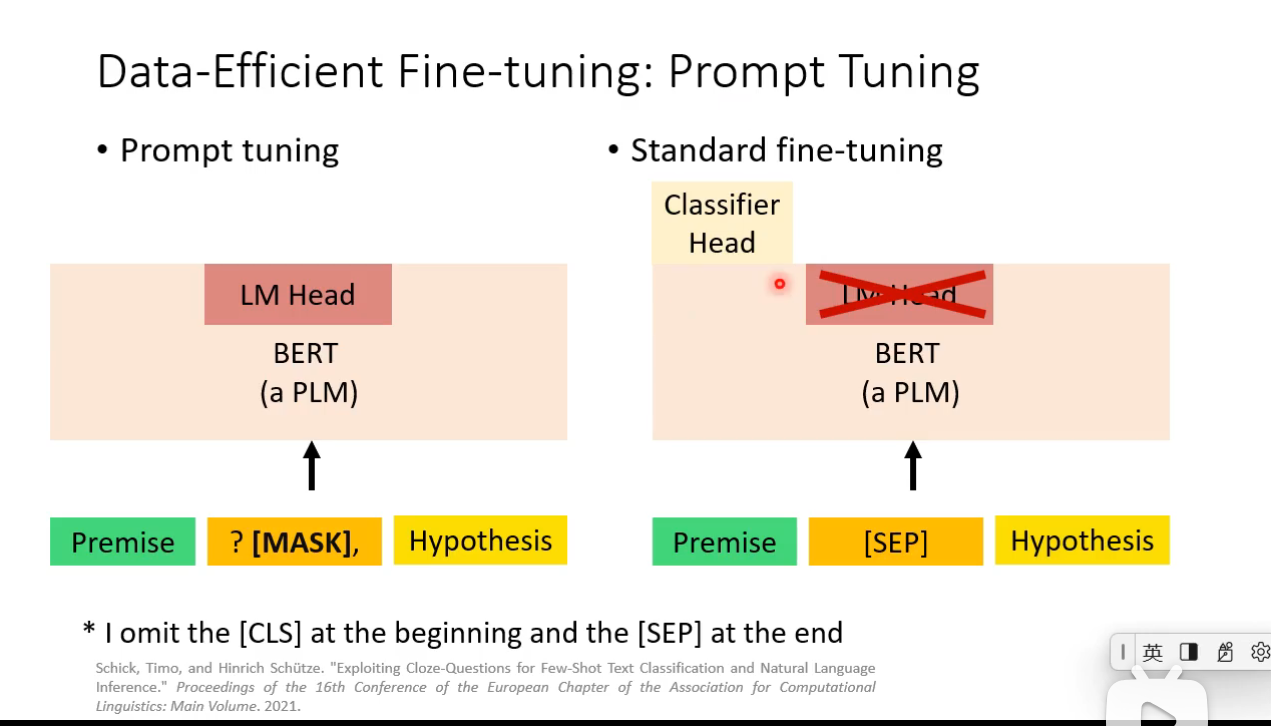
How prompt tuning be used in different level of labeled data scarcity
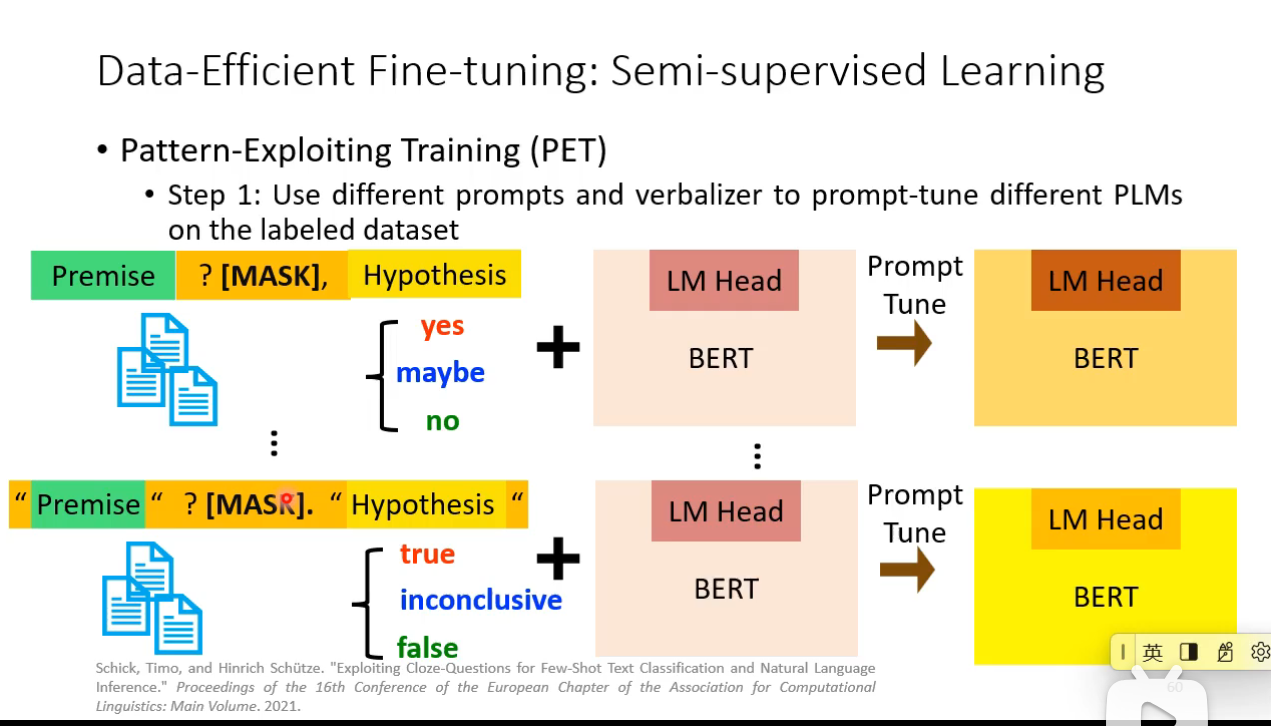
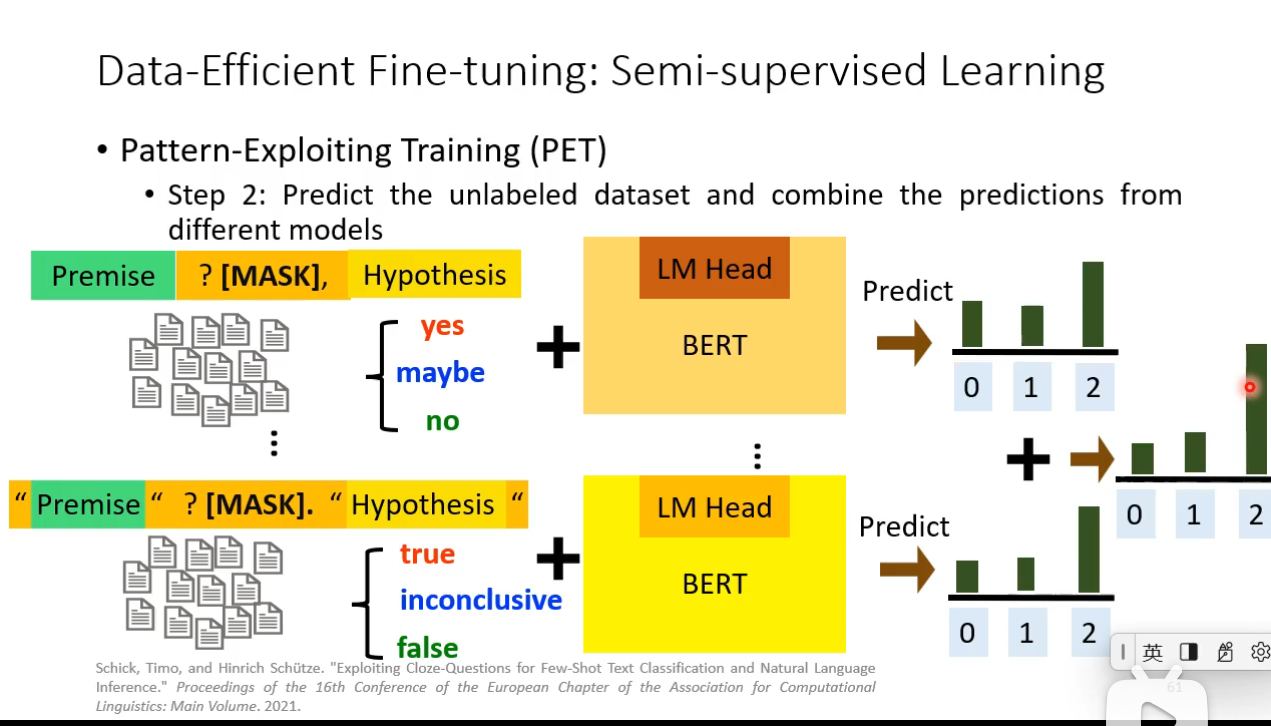
 ### Semi-supervised Learning
### Semi-supervised Learning
We have some labeled training data and a large amount of unlabeled data. And we want to try to label the unlabeled data.
PLM is too big
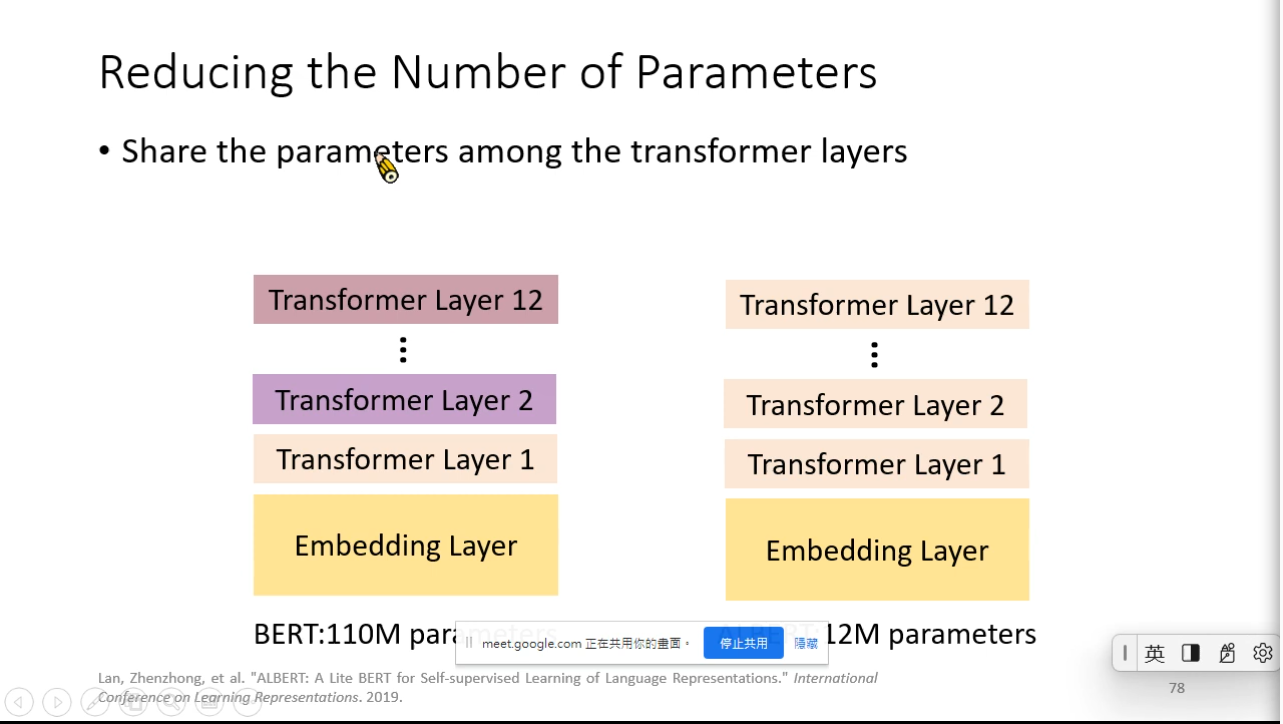
Reduce parameters scale while fine tuning 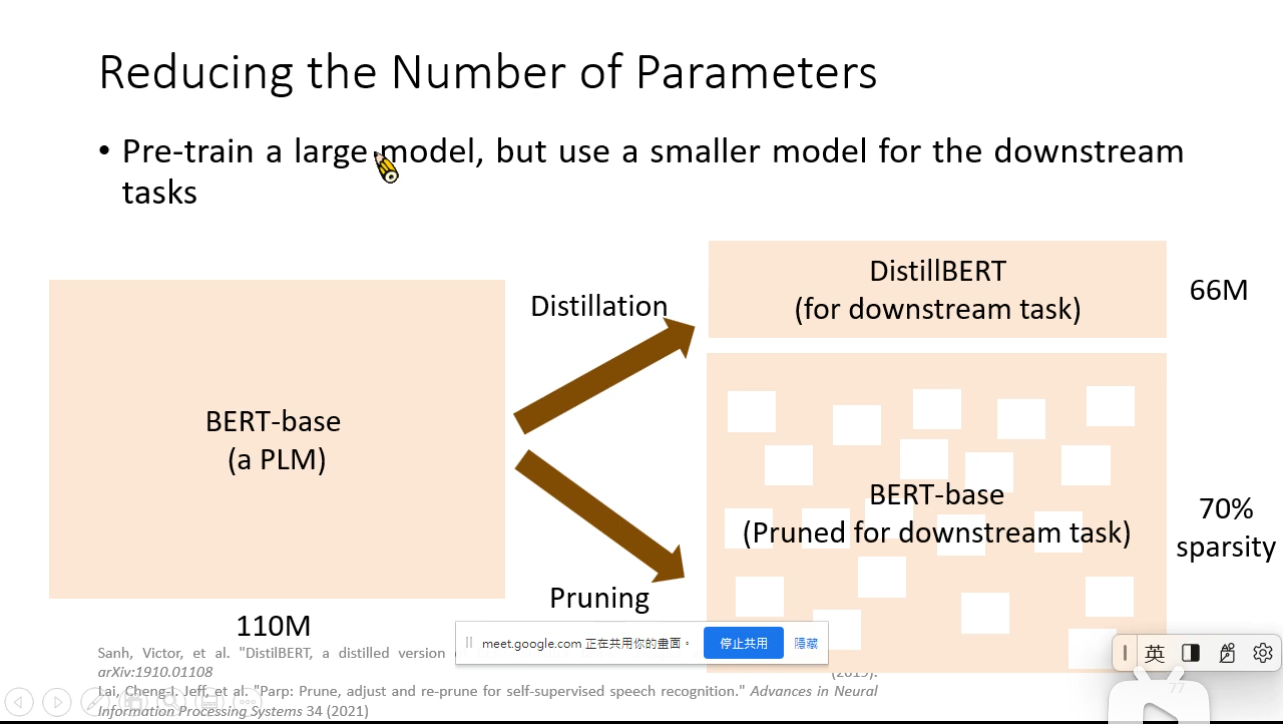
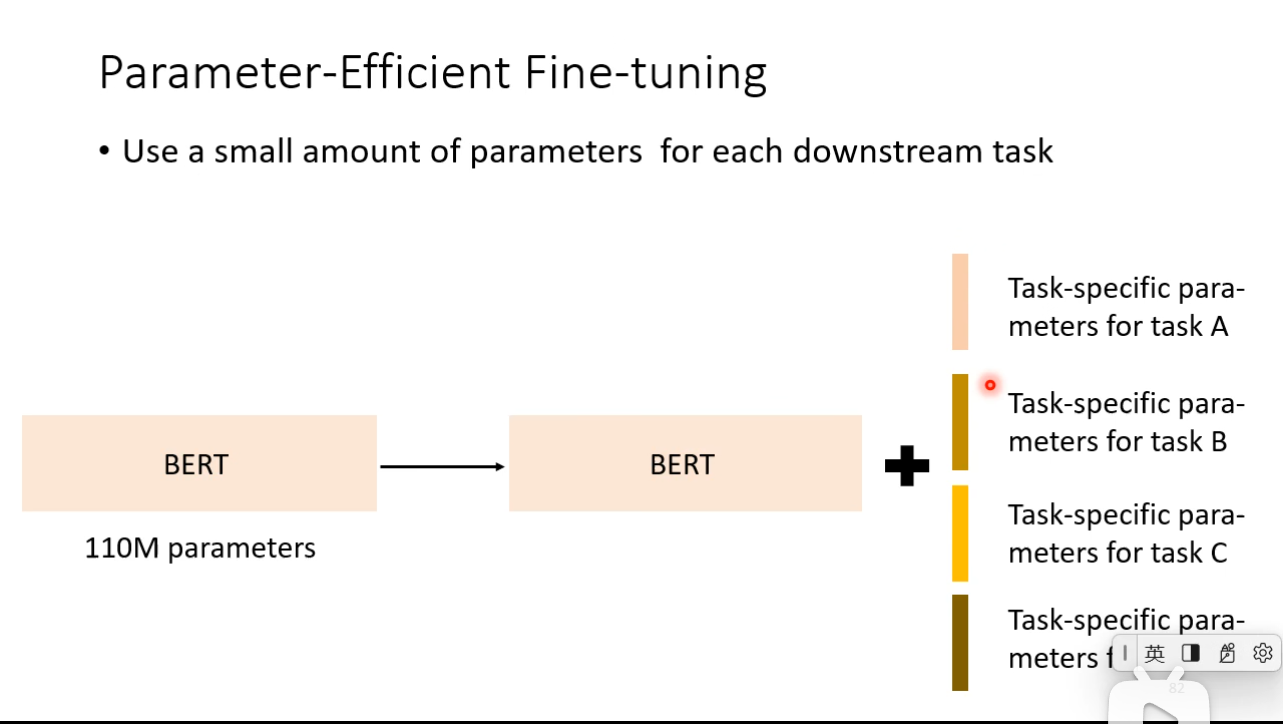
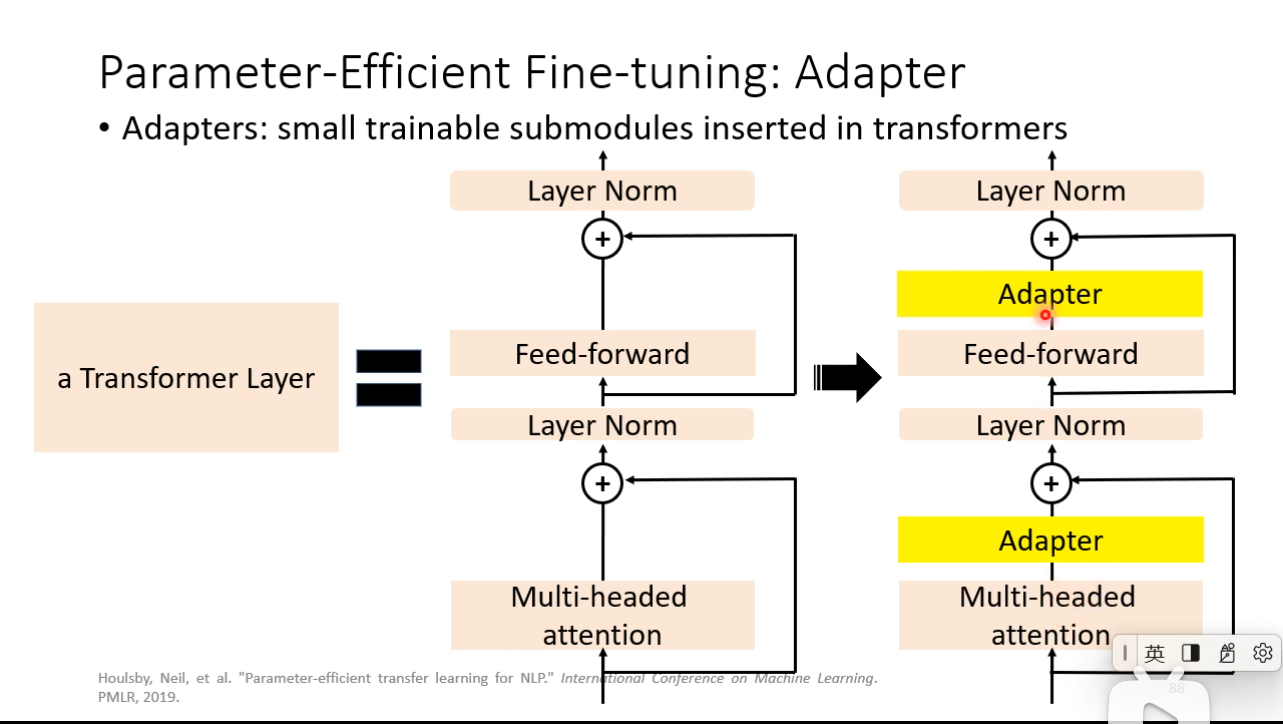
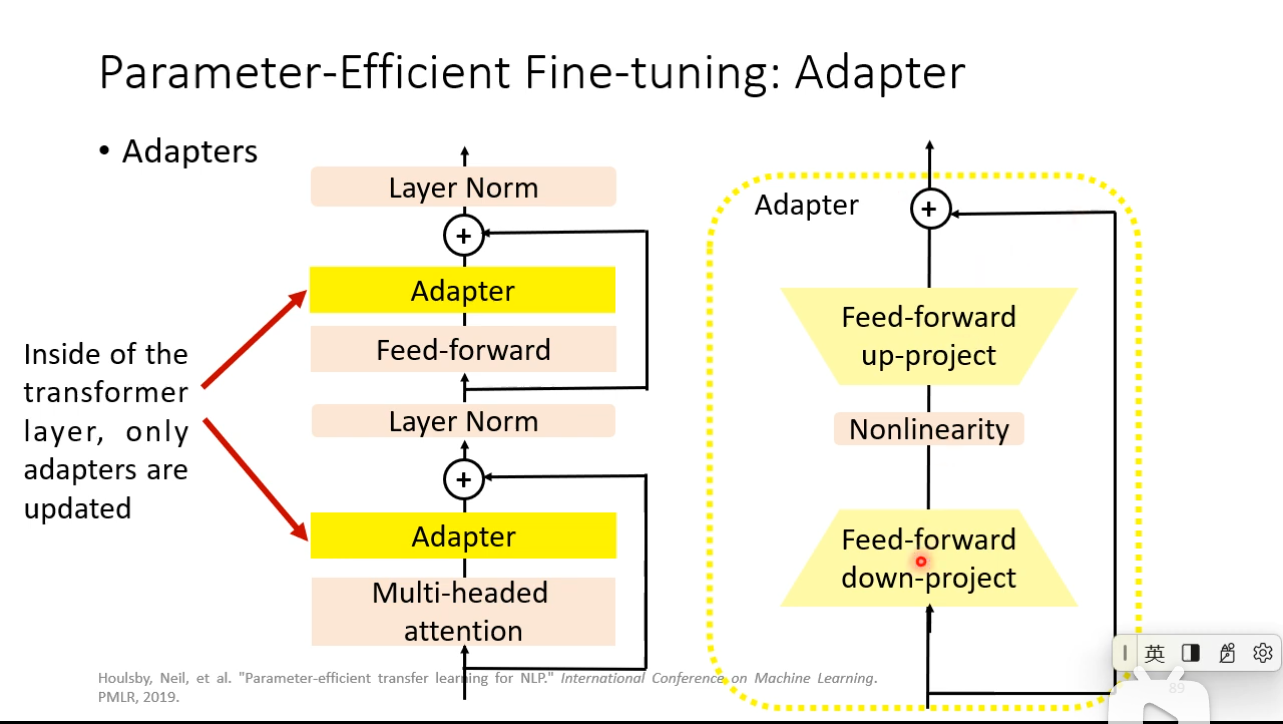
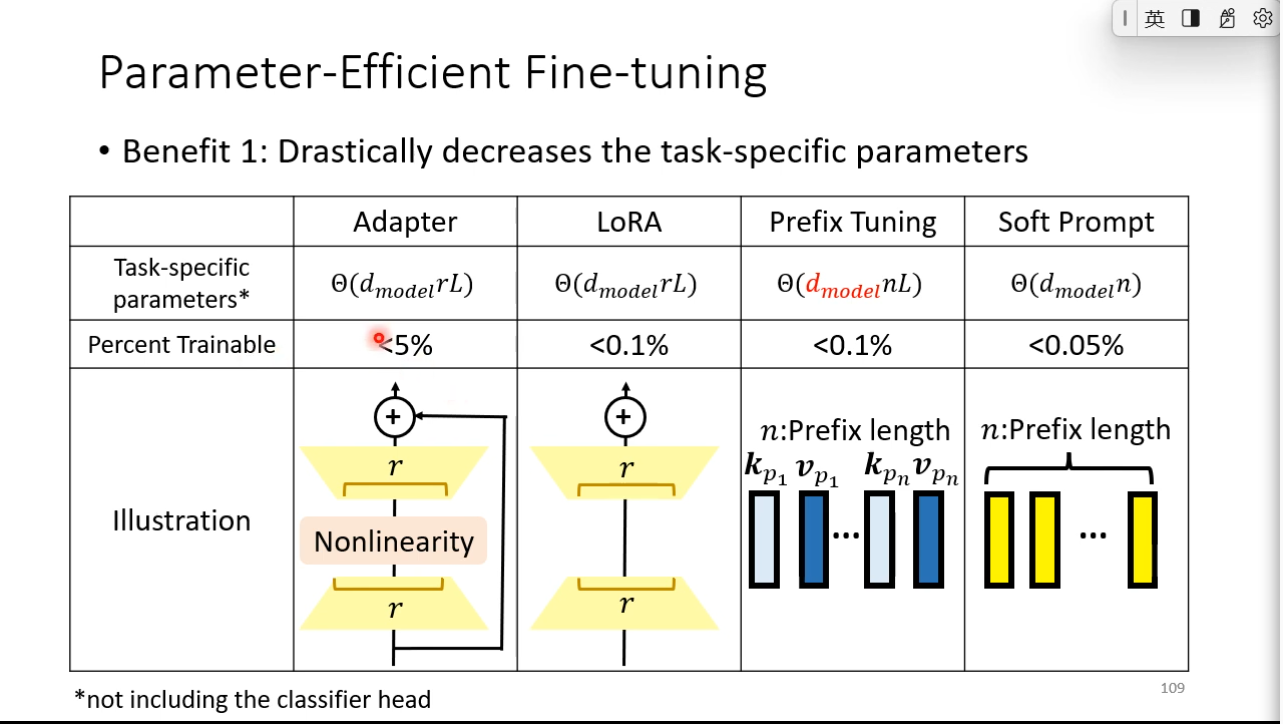
 ### Parameter-Efficient Fine-tuning
### Parameter-Efficient Fine-tuning
- Use a small amount of parameters for each downstream task
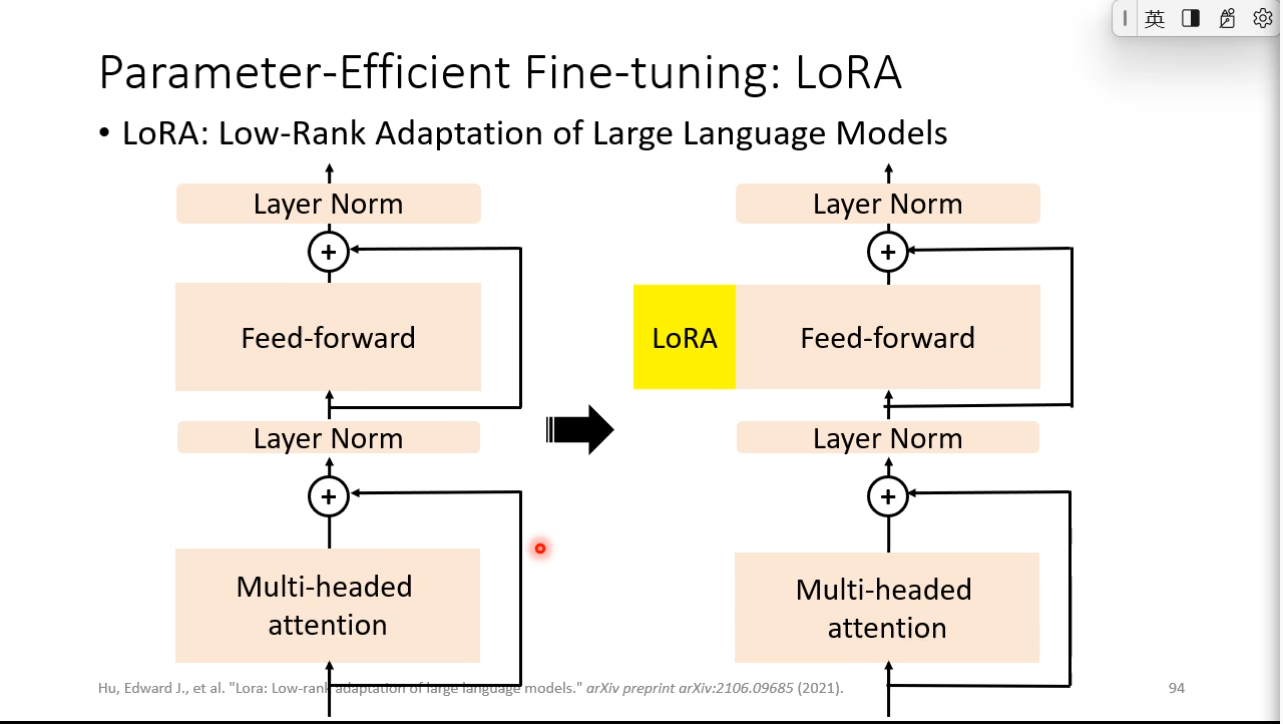
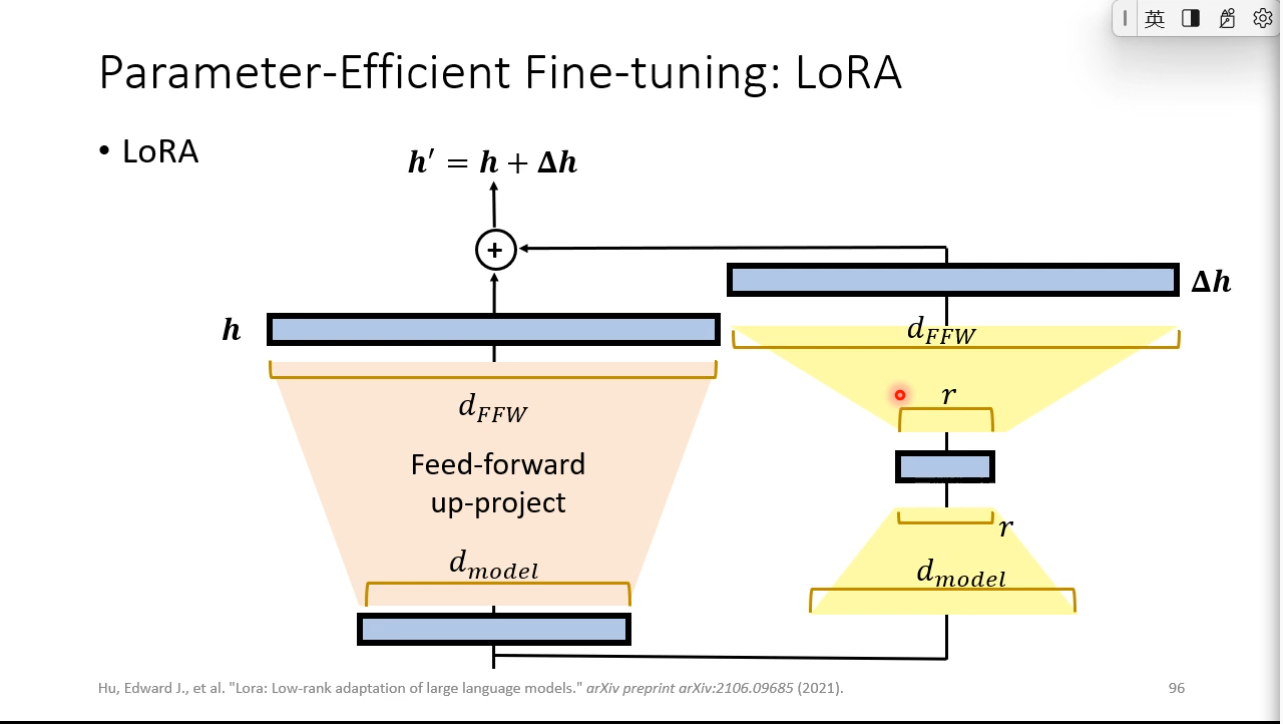
 ### LoRA
### LoRA
 ### Prefix Tuning
### Prefix Tuning 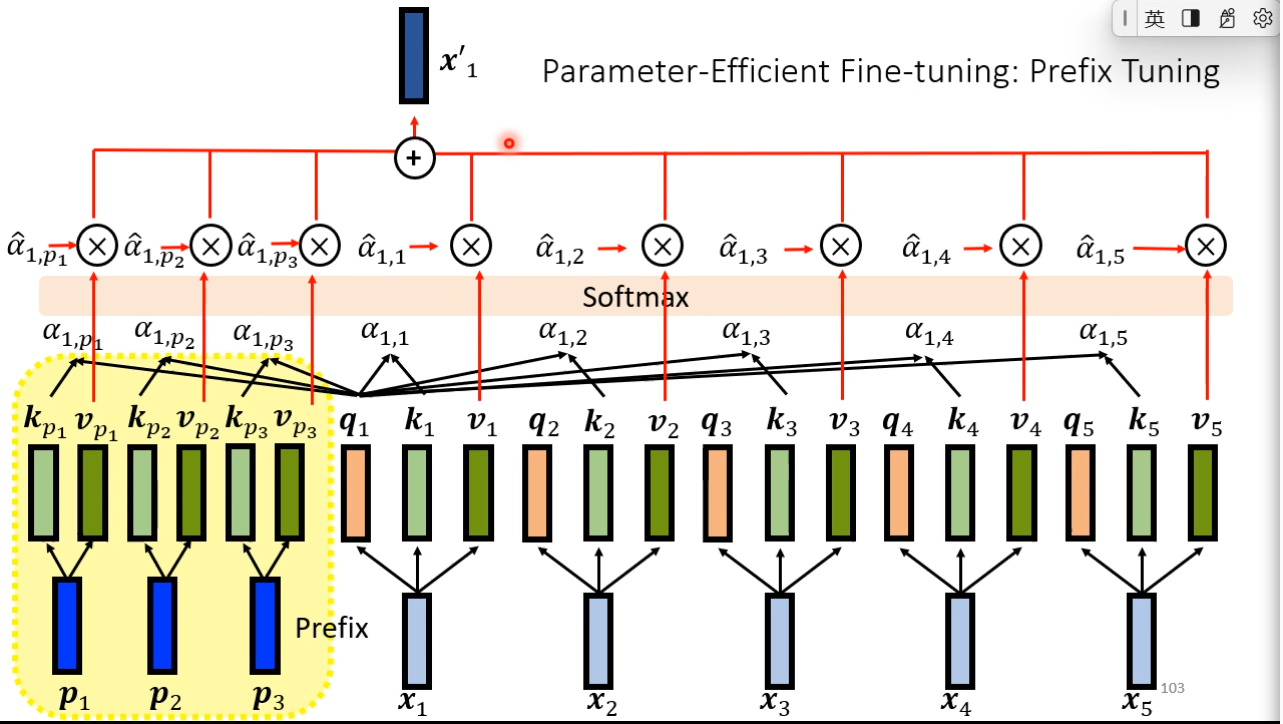
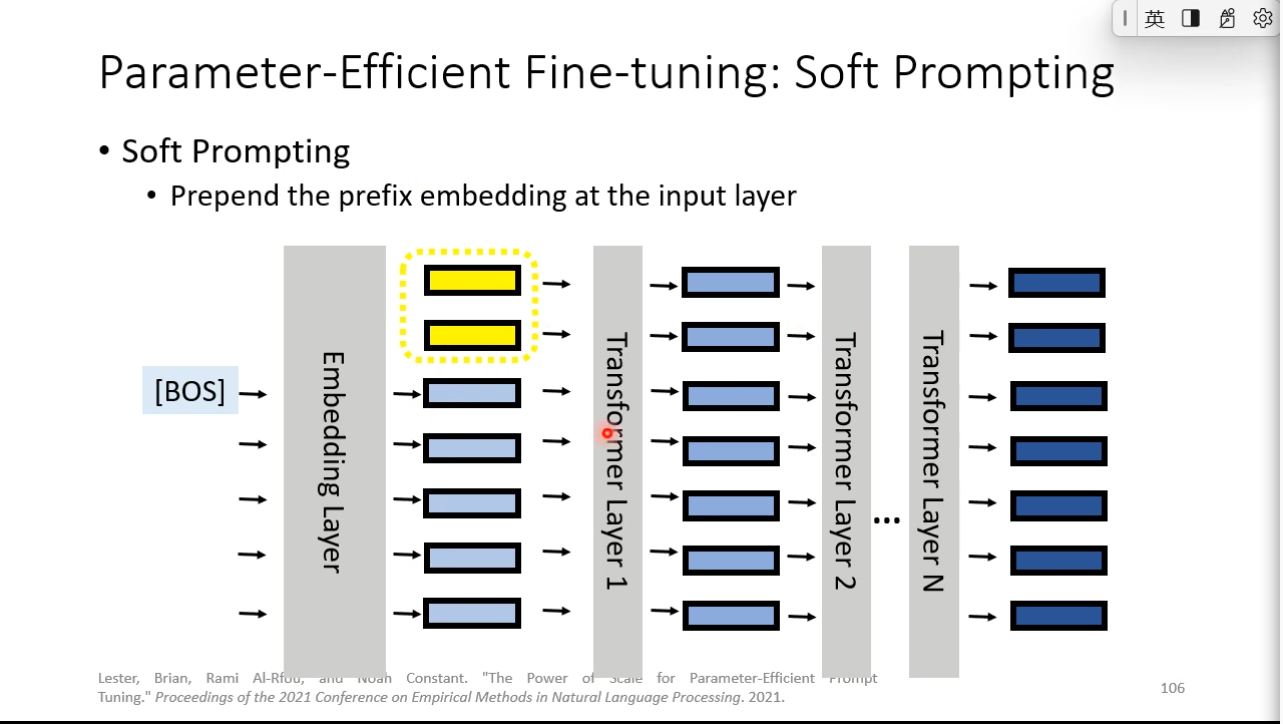
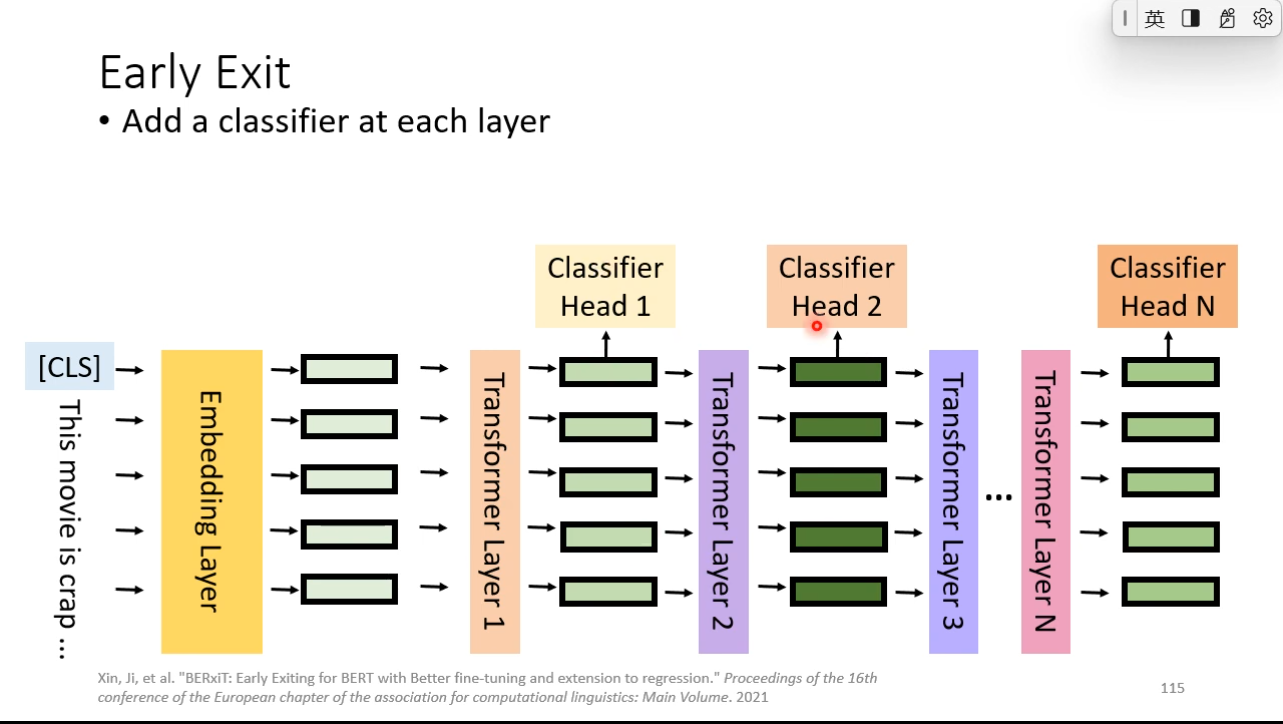
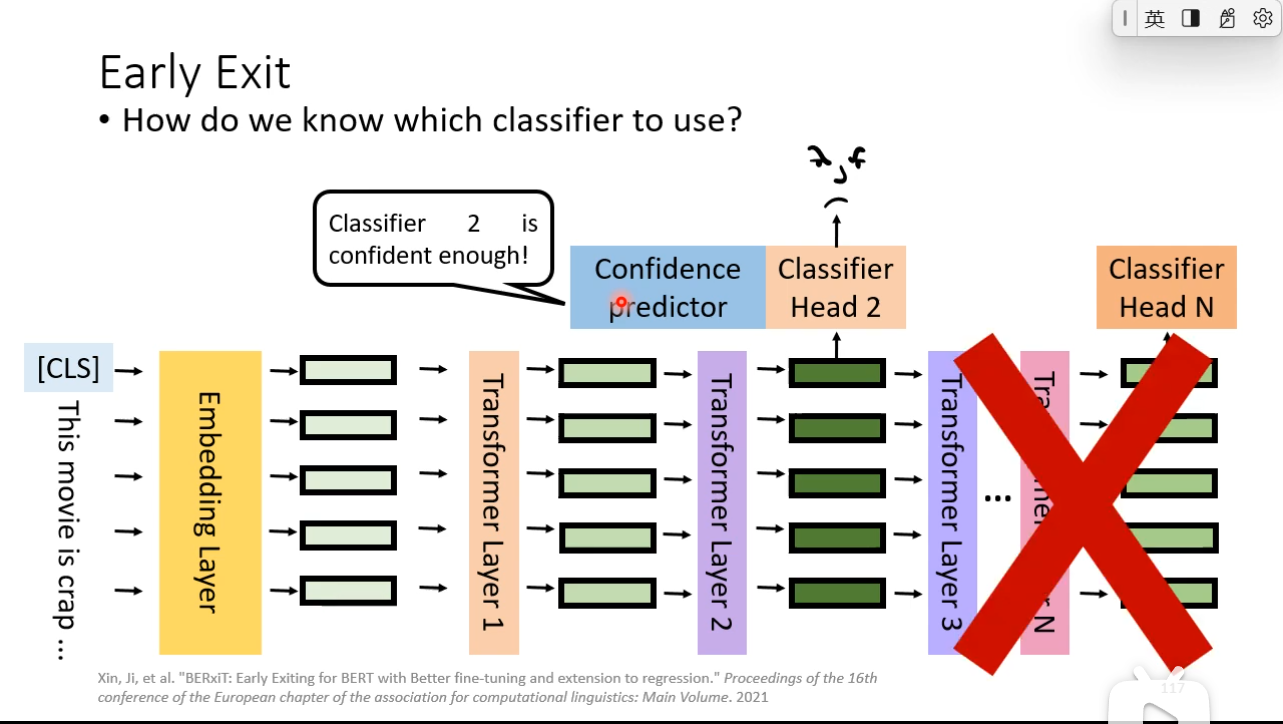
Early Exit
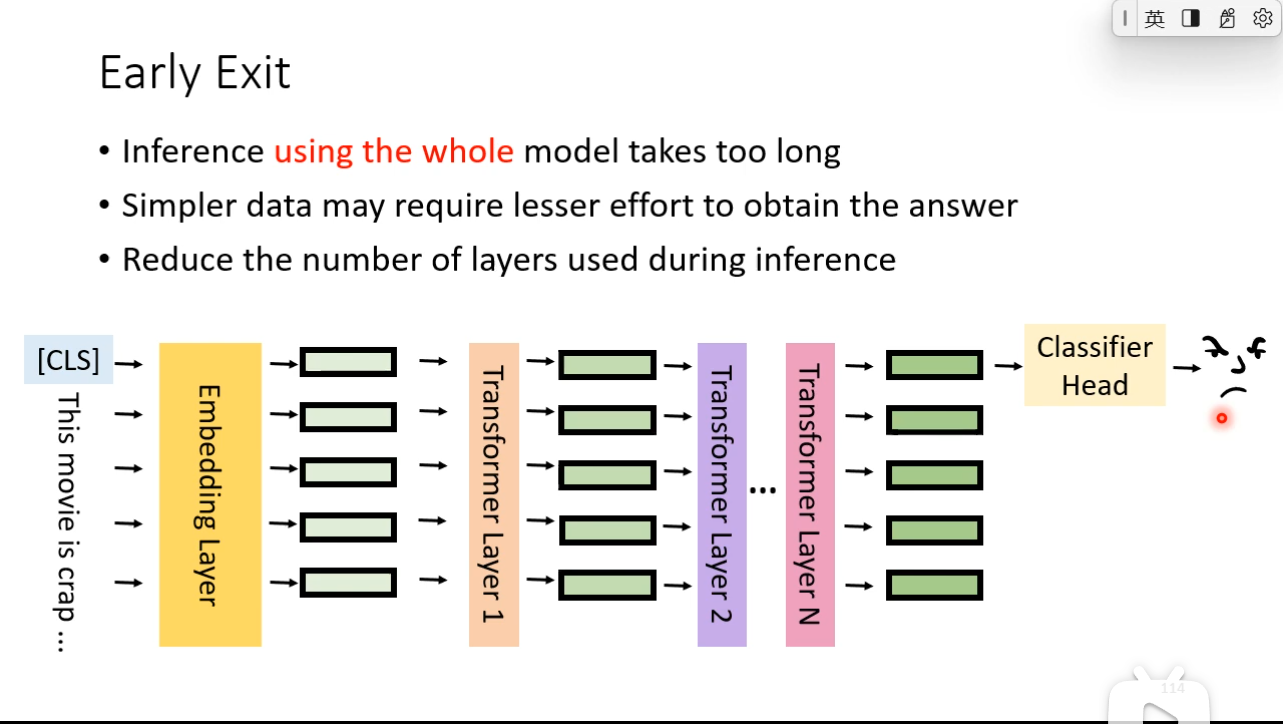
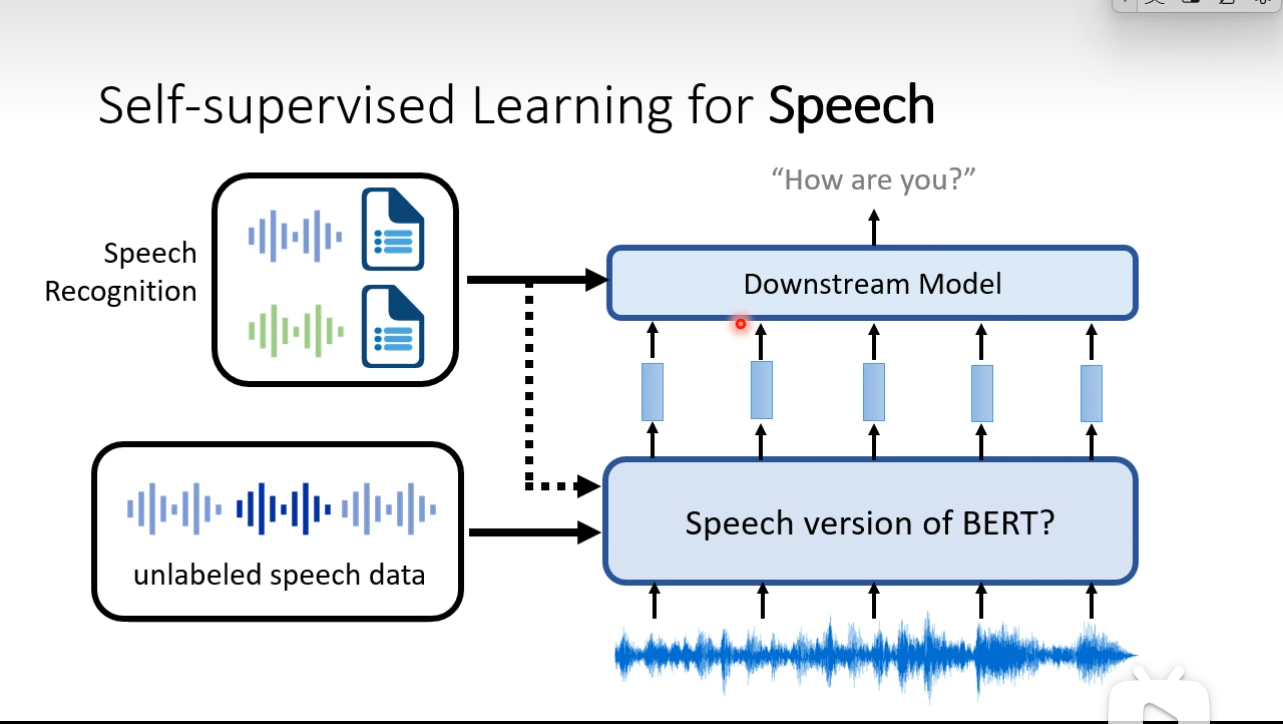
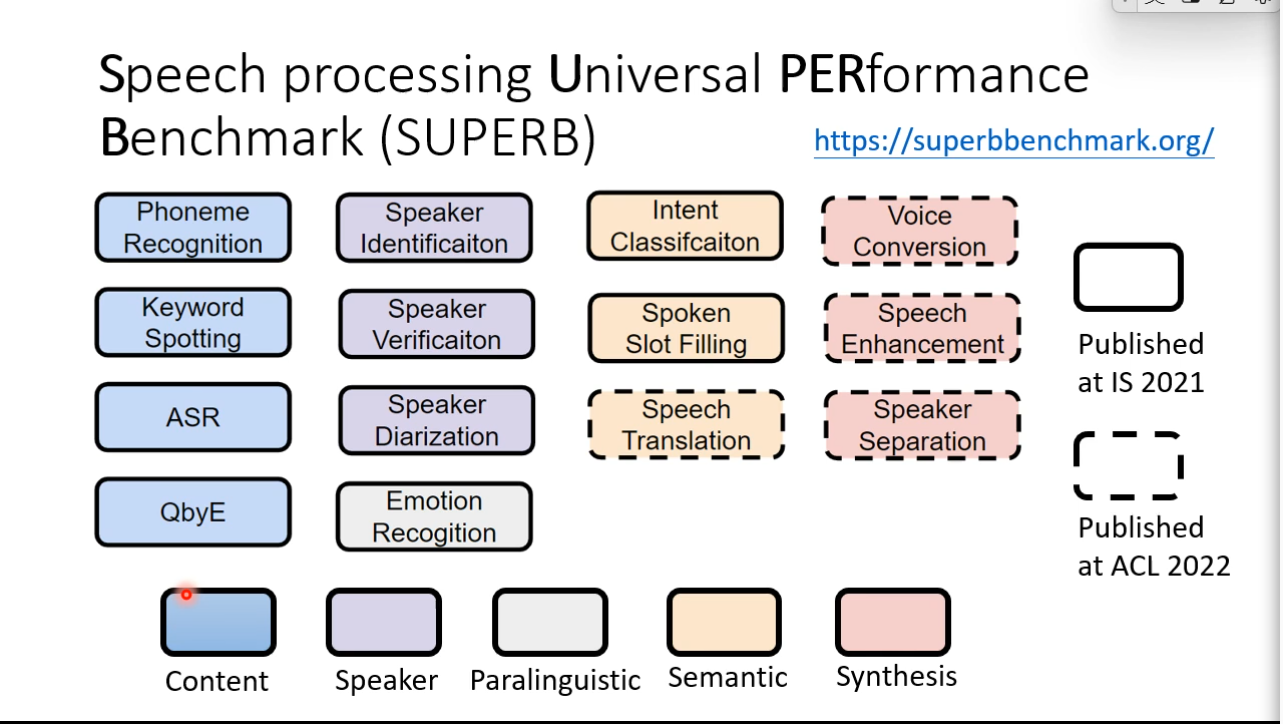
Self-supervised Leaning for speech and image
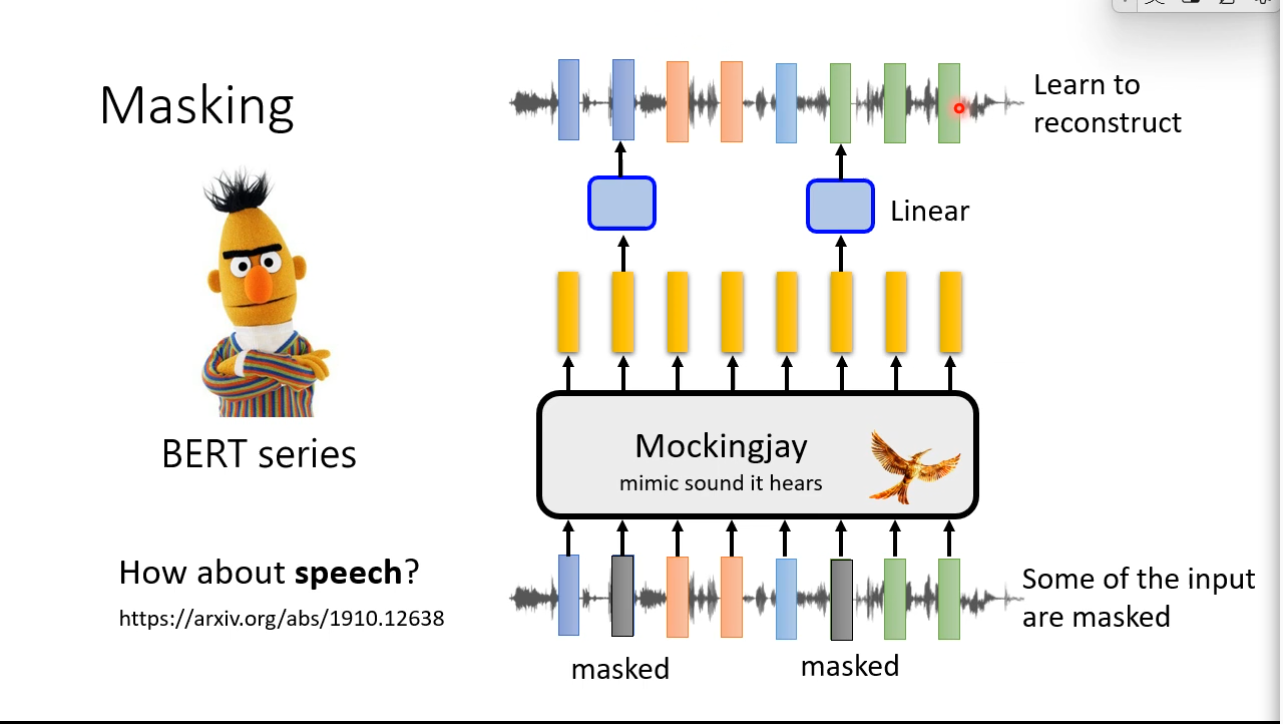
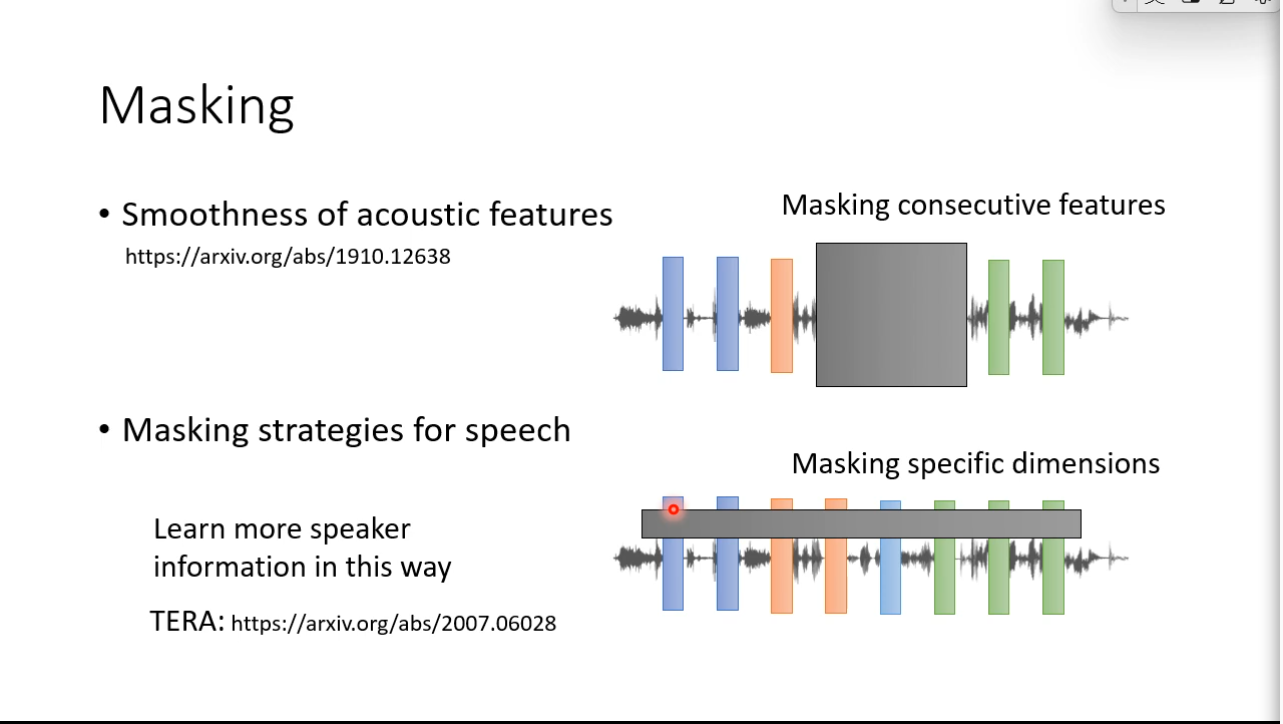
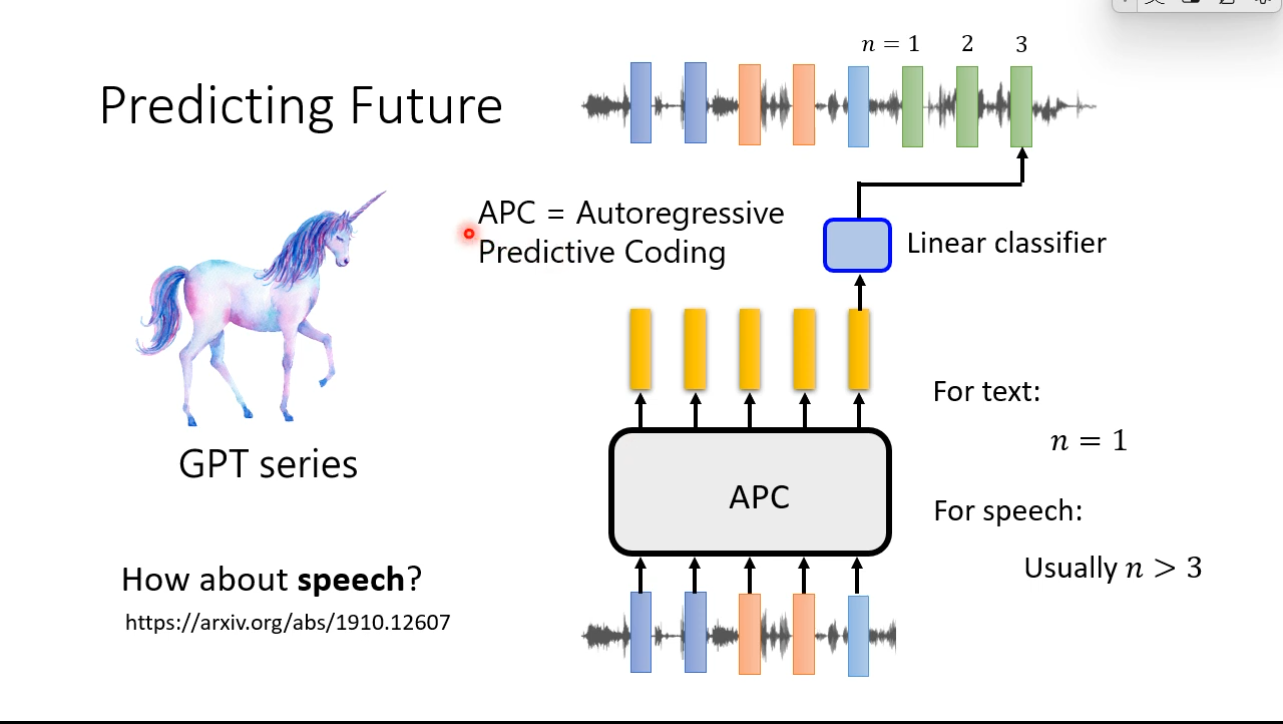

Predictive Approach
Speech and images contain many details that are difficult to generate, but there is a way to learn without generation. 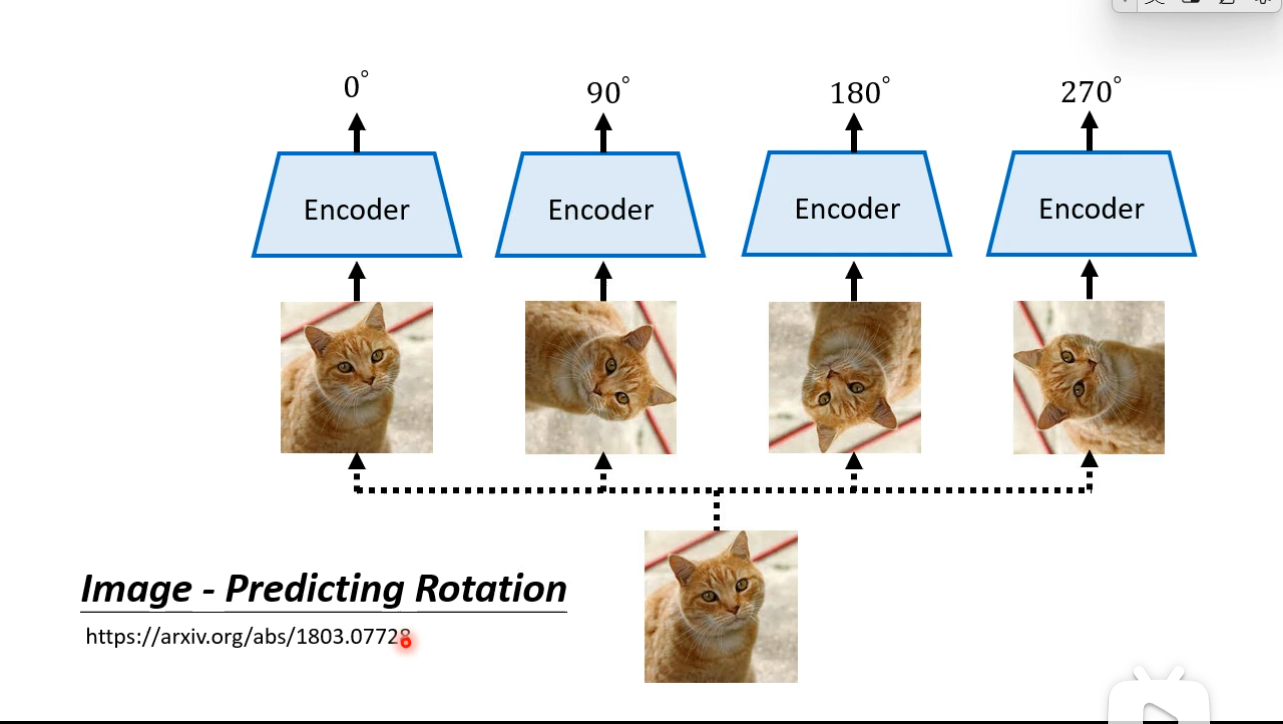
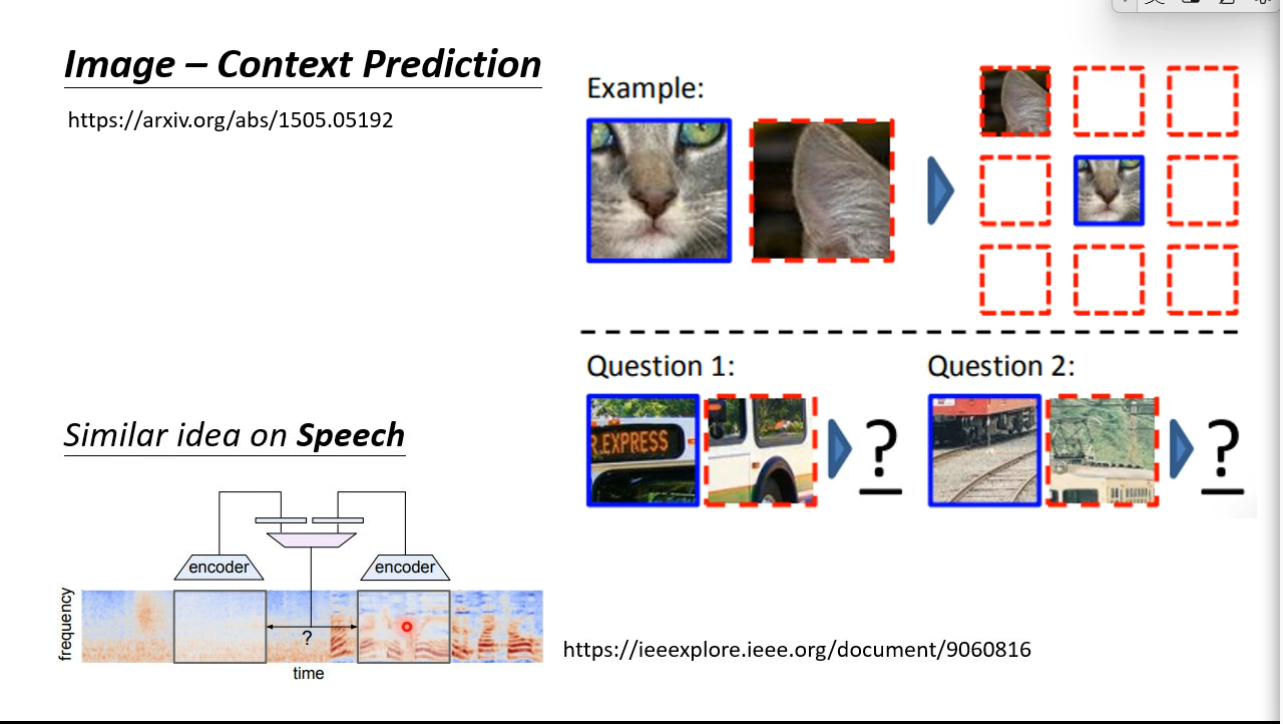
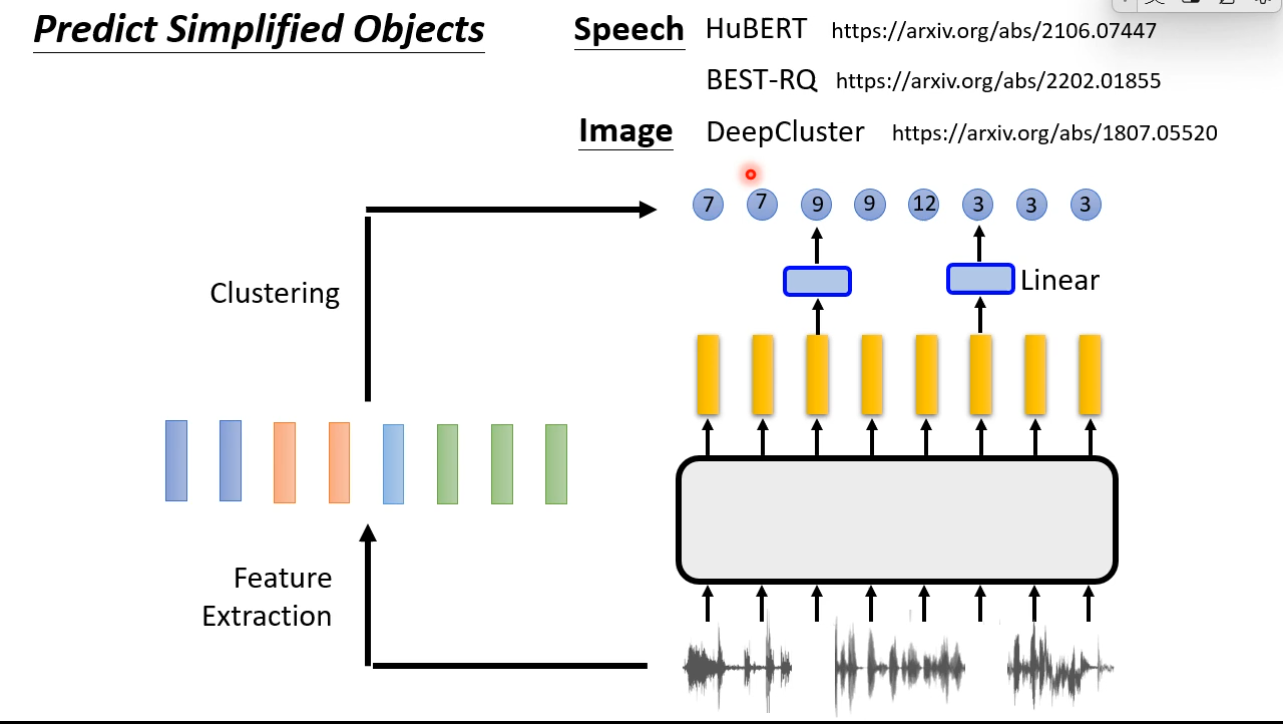
Contrastive Learning
Find some positive samples, make the, as close as possible. And negative samples as far as possible. 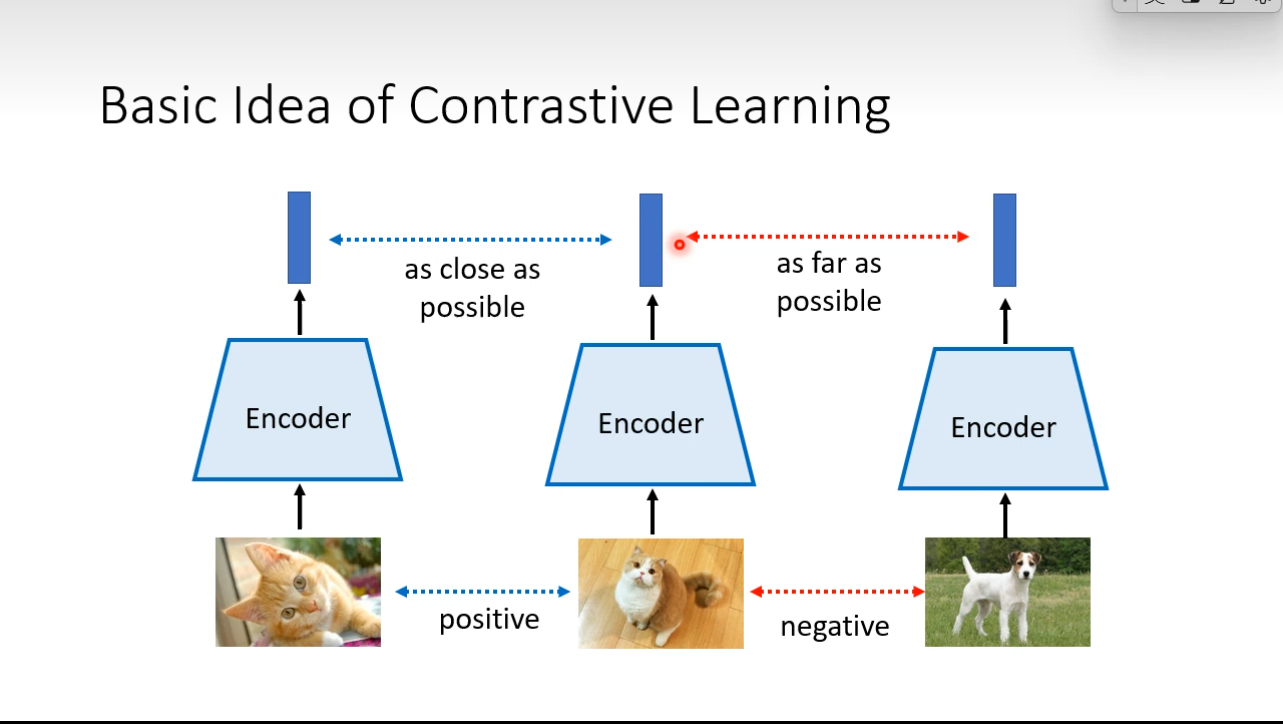
However, considering that the job is a self-supervised job, we do not know labels of samples ### SimCLR 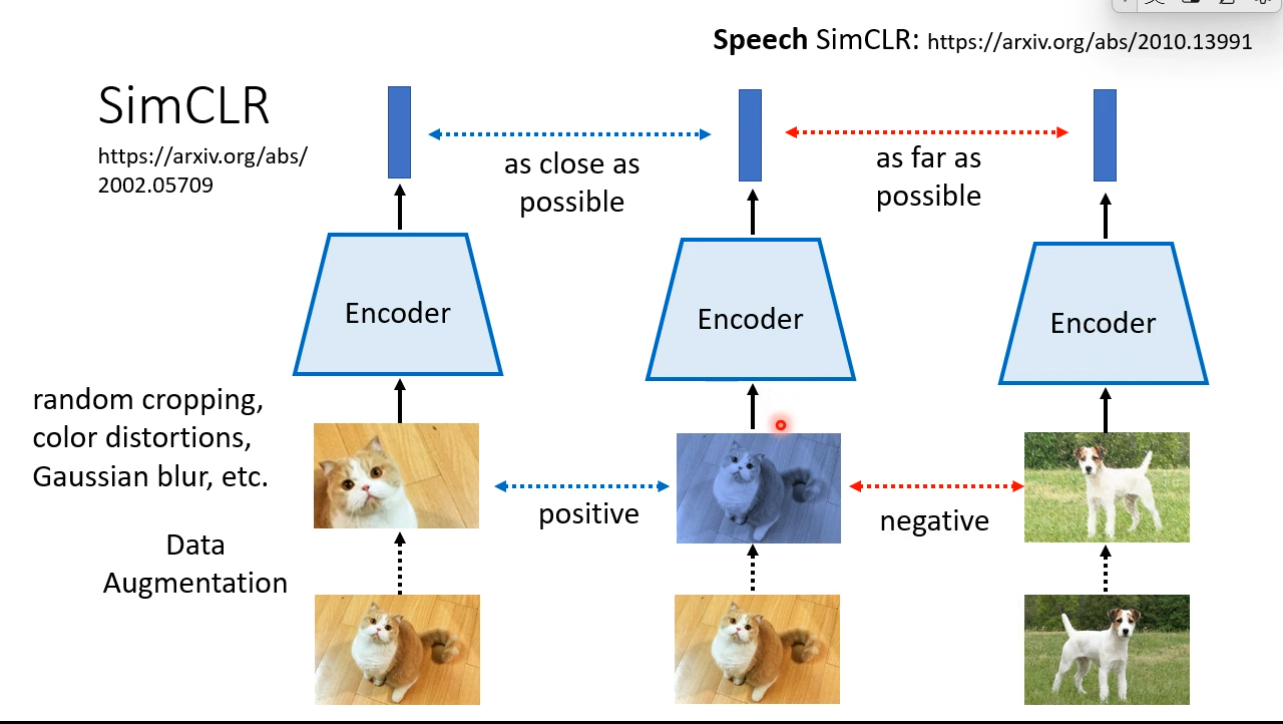 ## Moco
## Moco 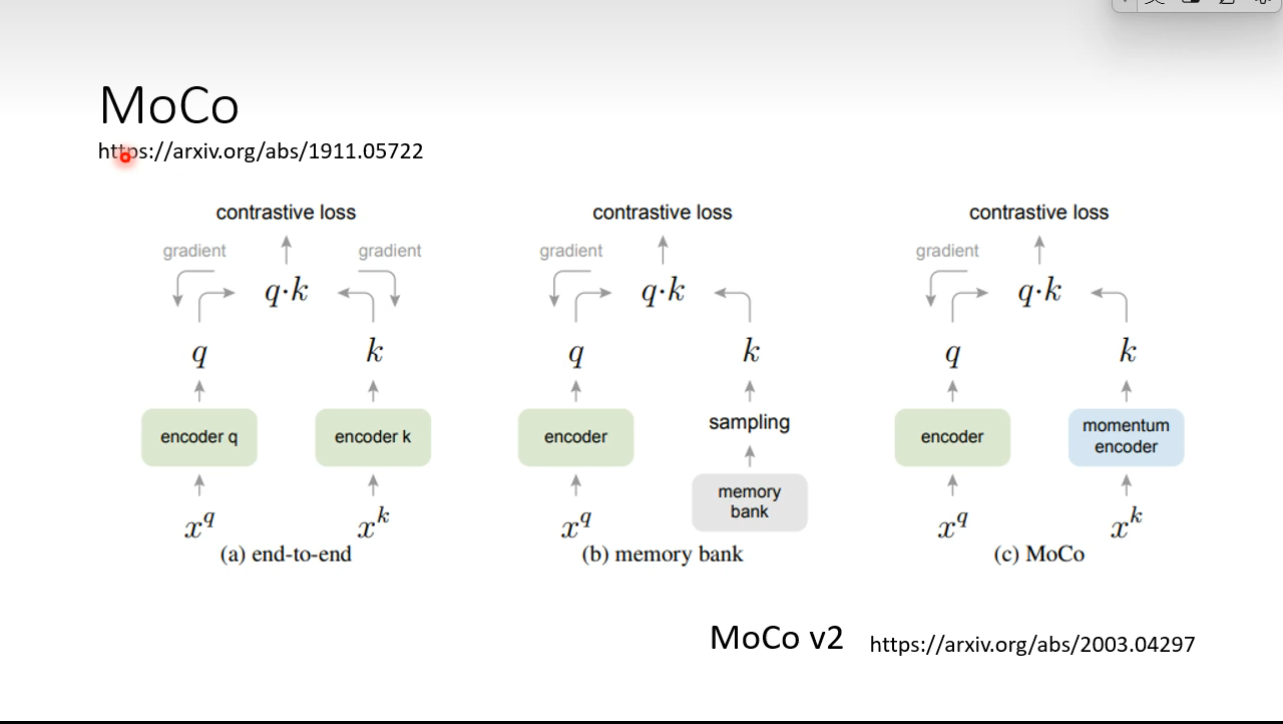 ## Contrasitive Learning for Speech
## Contrasitive Learning for Speech 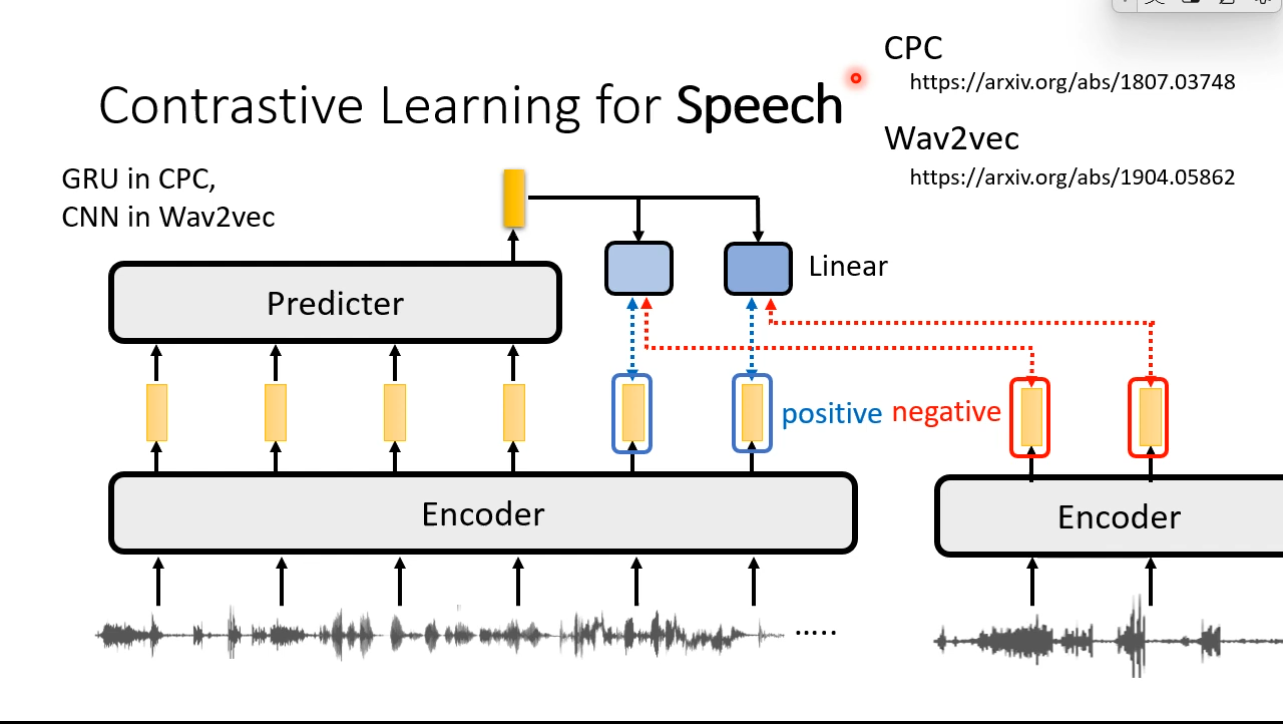
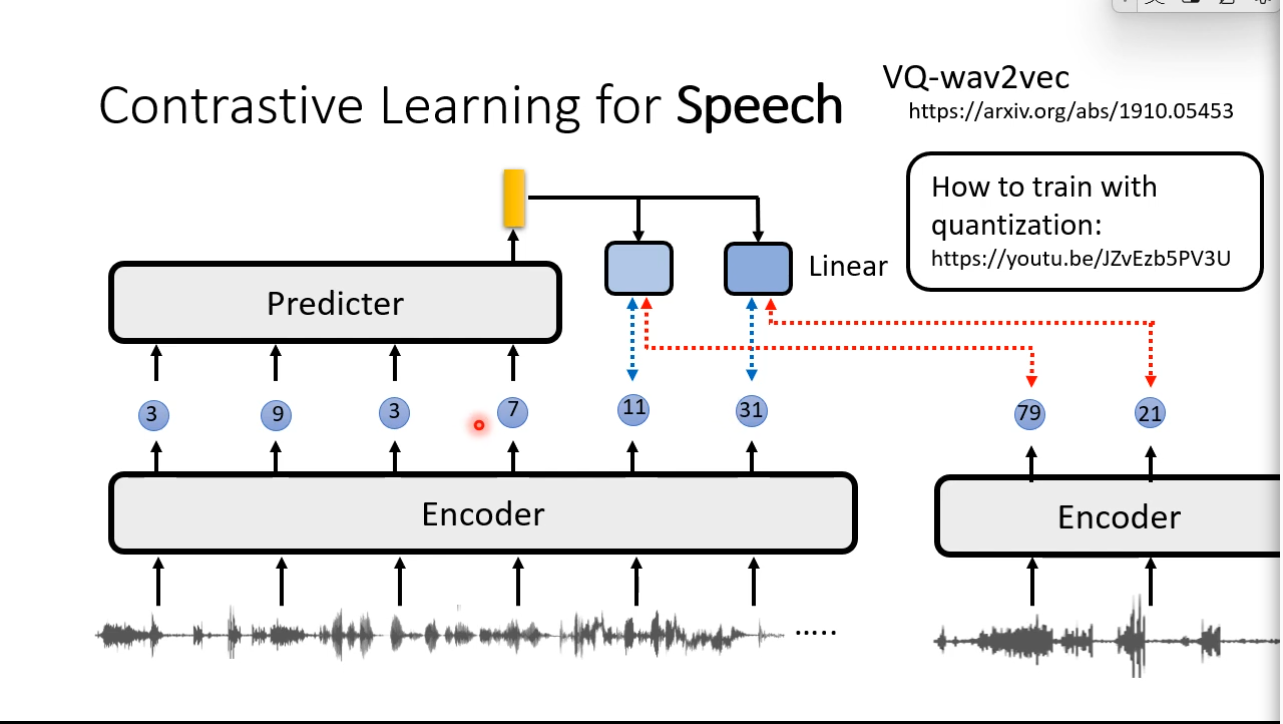
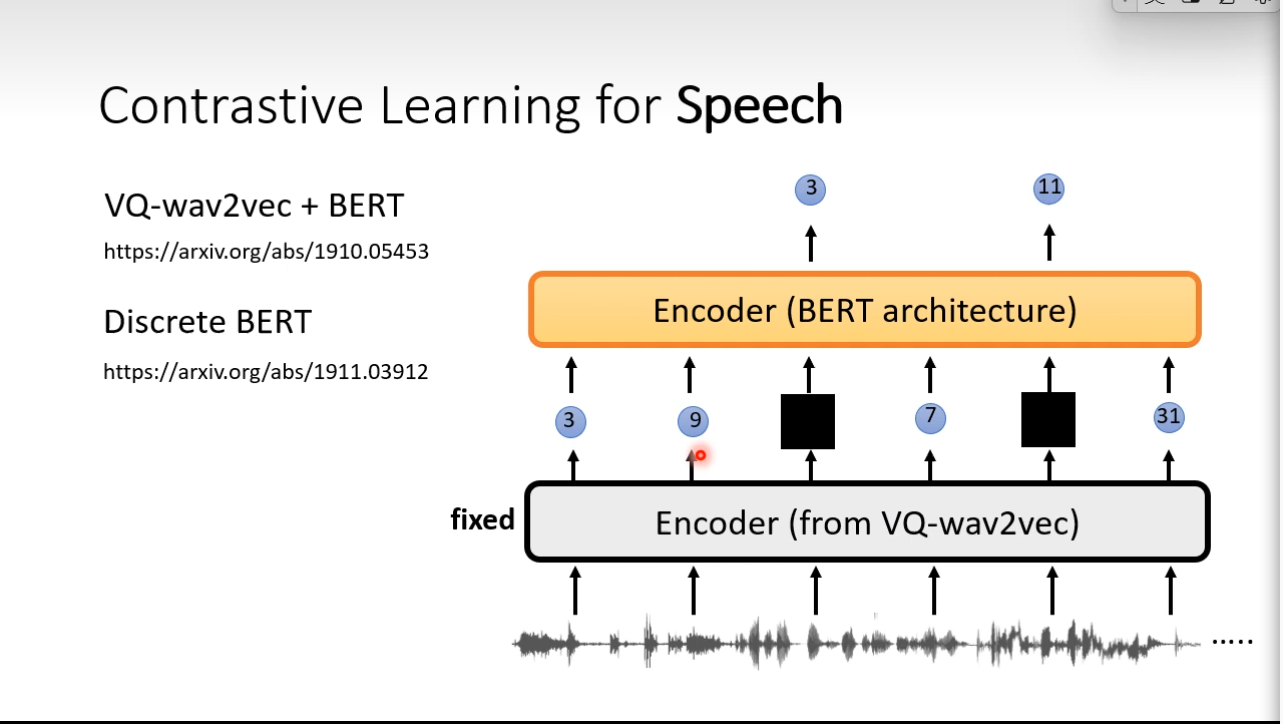
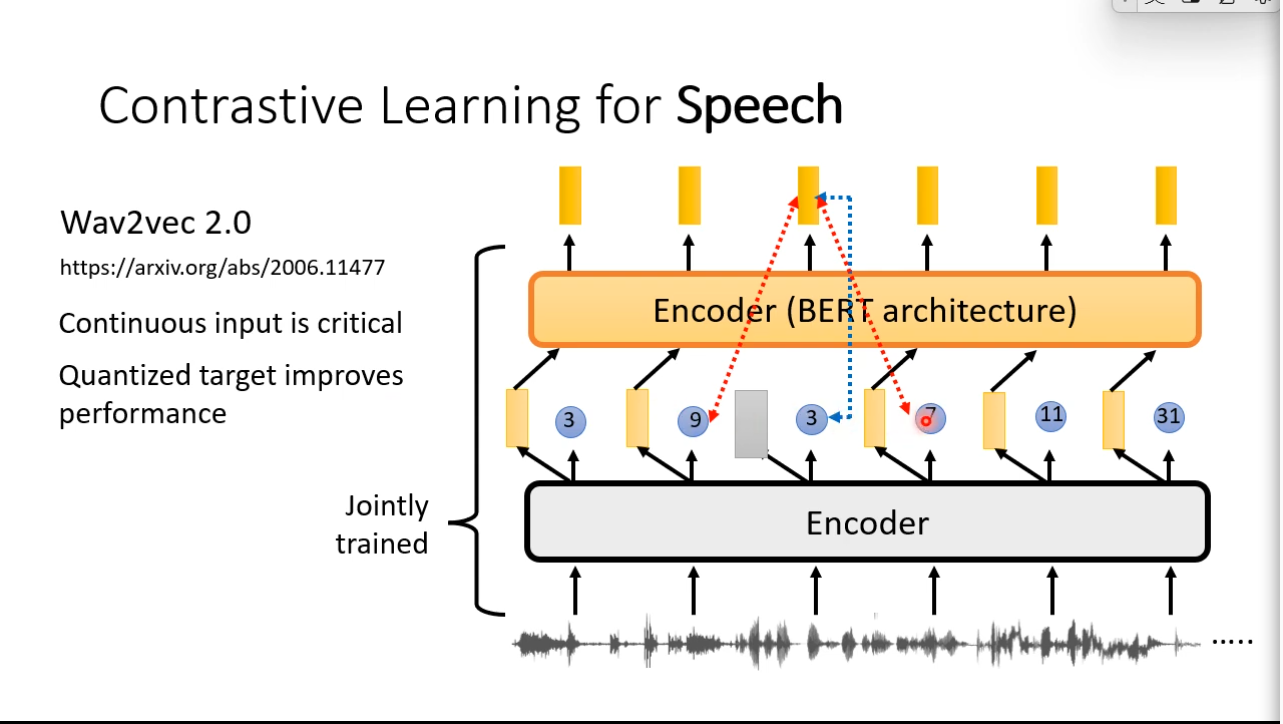
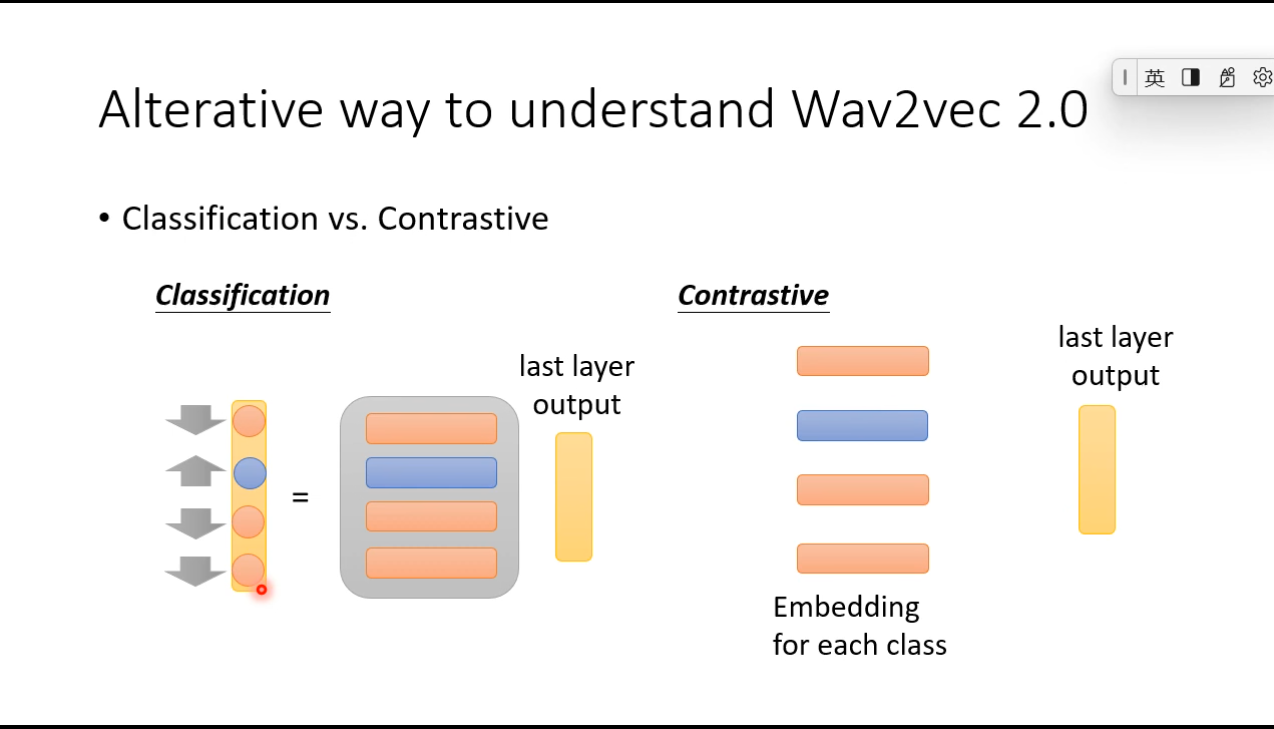
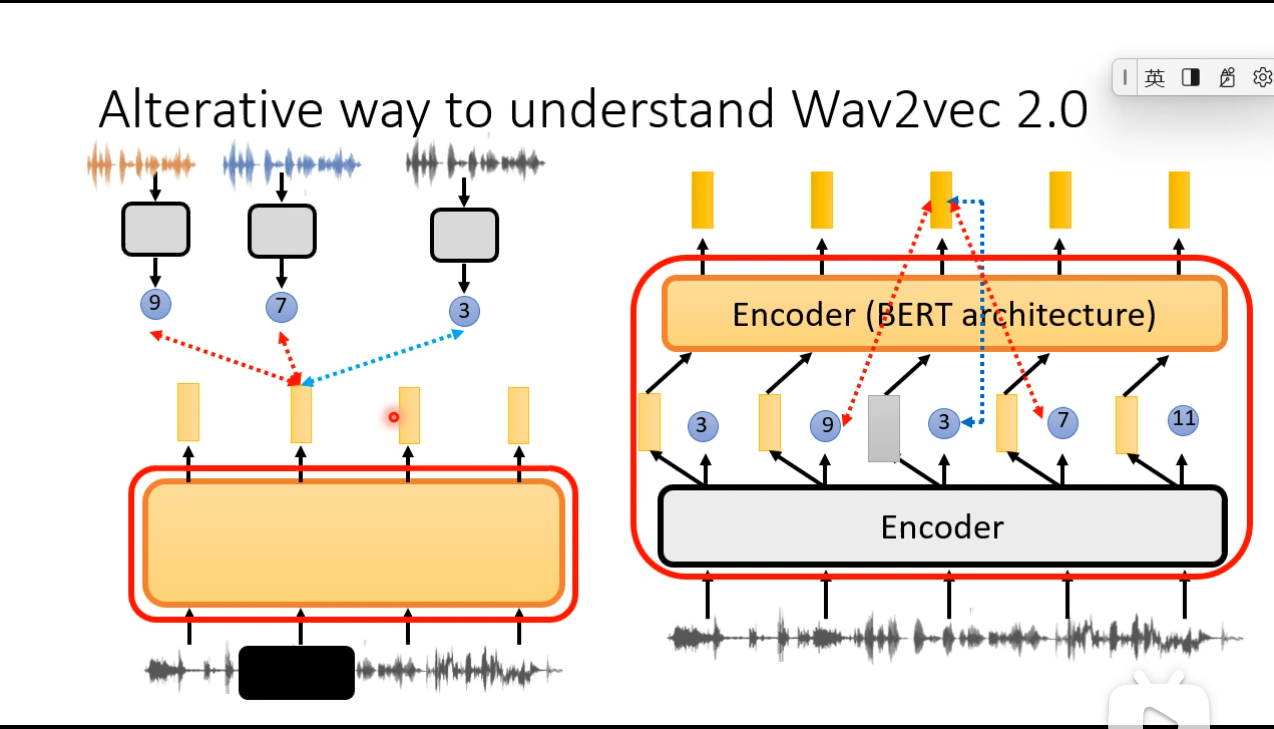

Bootstrapping
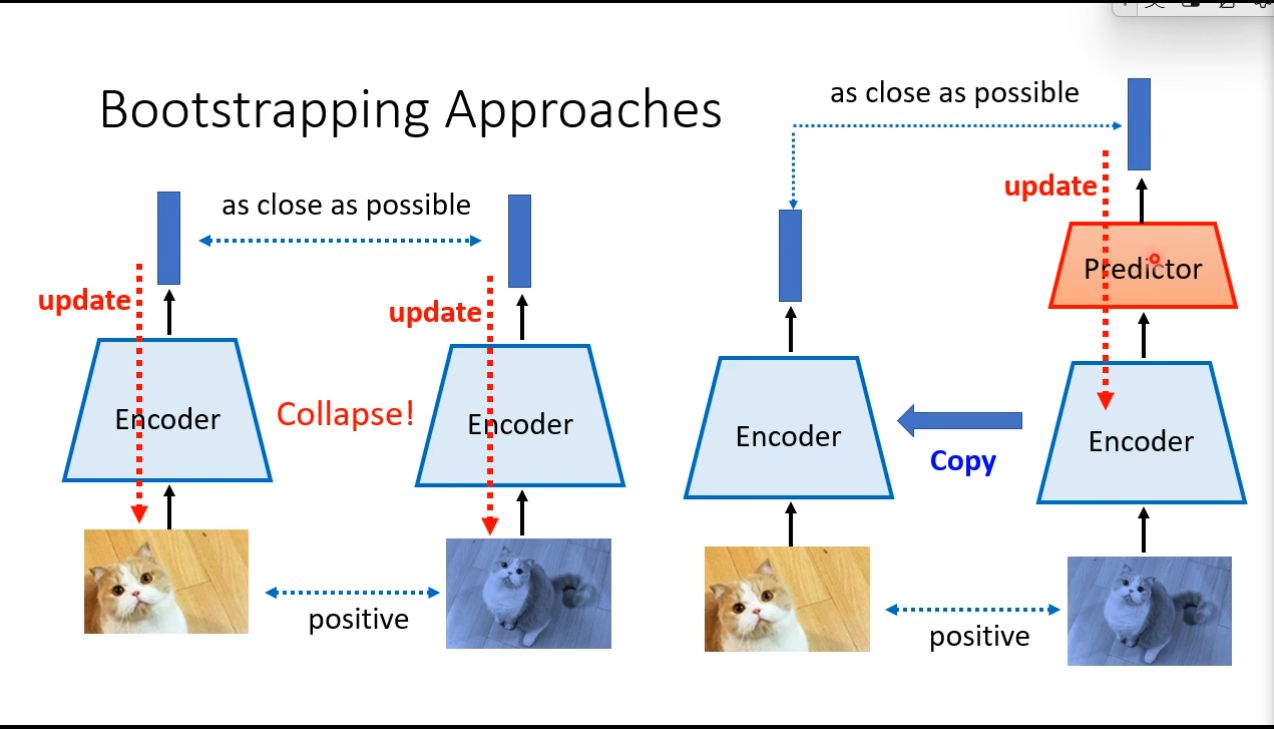
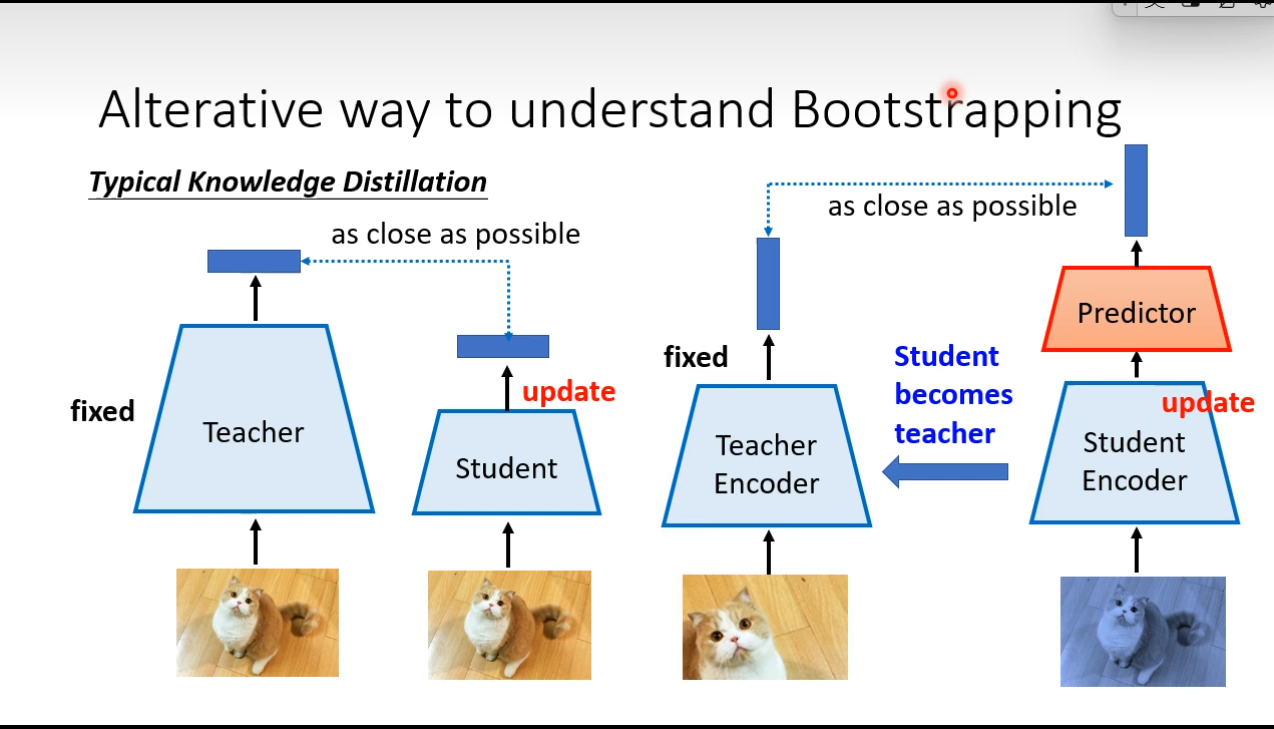
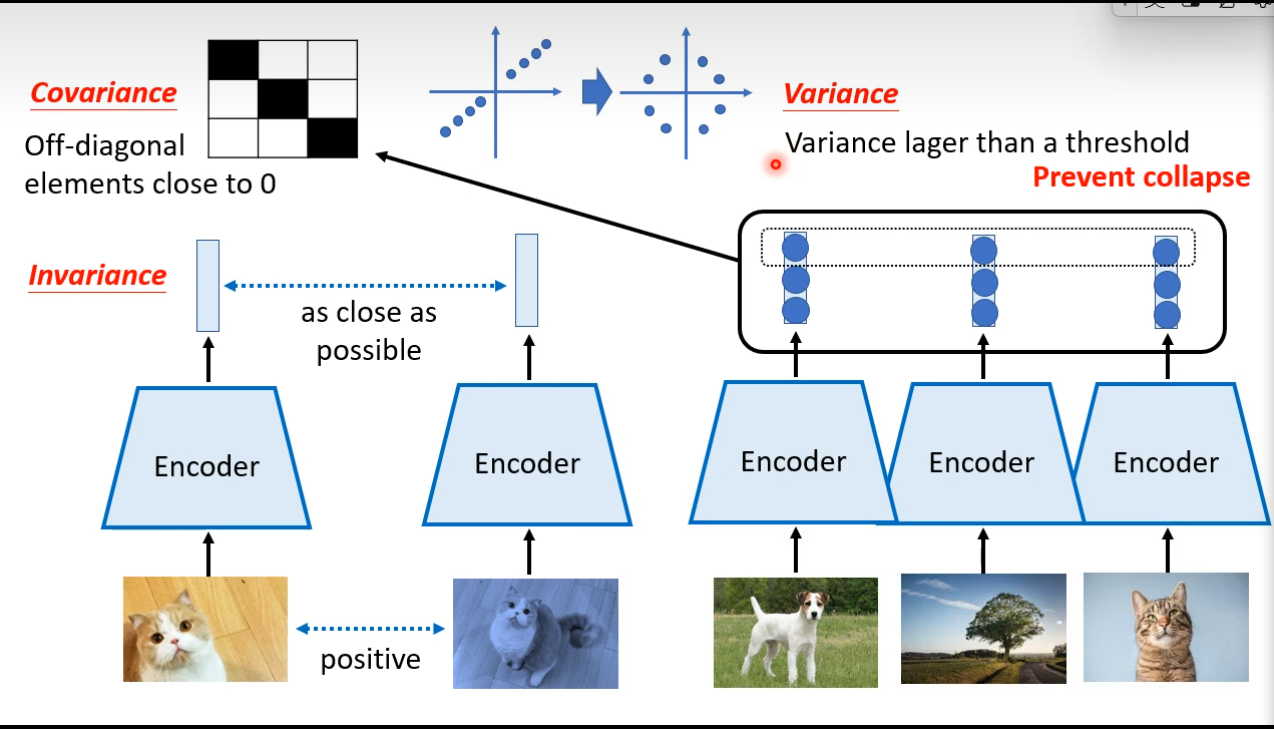 、
、