自注意力机制(Self Attention)
输入的向量集
- One-hot 编码
- 词嵌入 (word embedding) ## 输出
- 每个向量对应一个标签(序列标注)
- 整个序列有一个标签
- 模型可以自行决定标签数量(seq2seq)
序列标注 (Sequence Labeling)
- 可以考虑上下文信息
- 将整个序列放在一个窗口中计算可能会消耗大量资源
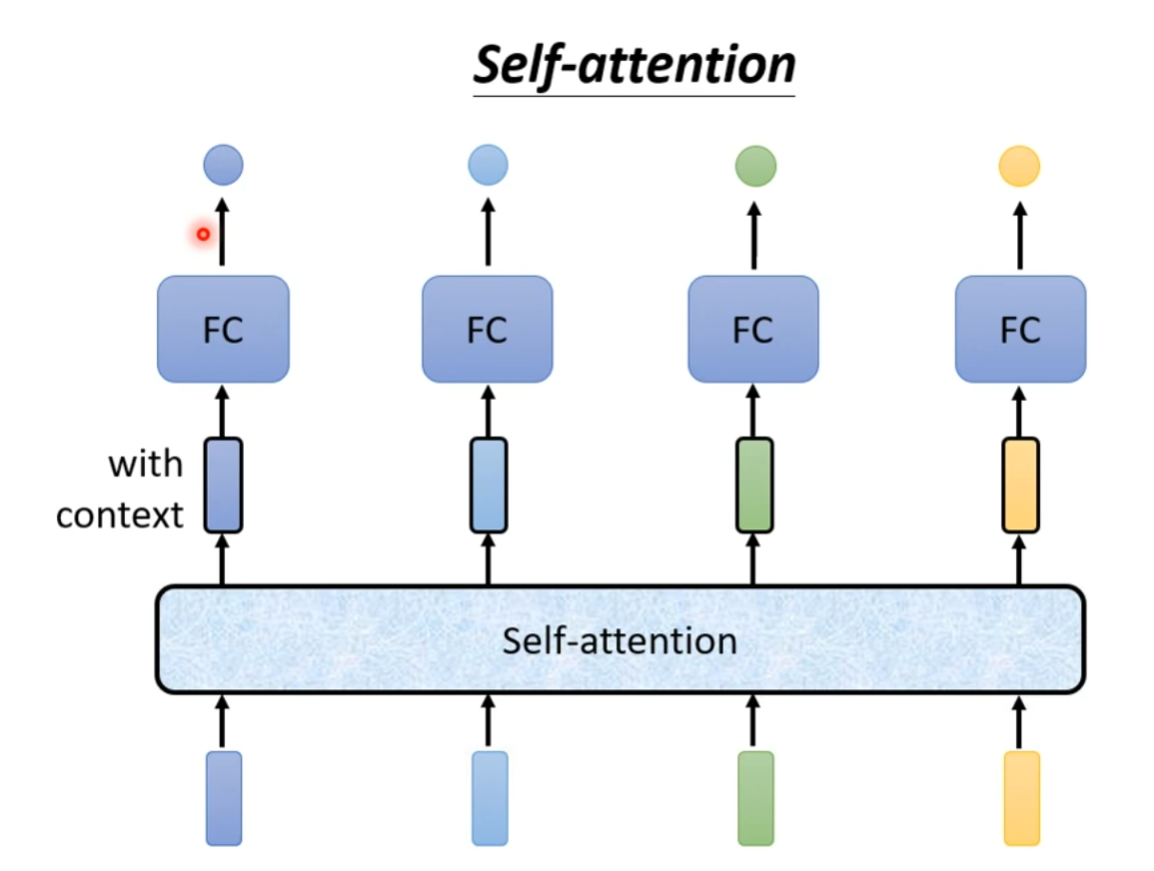
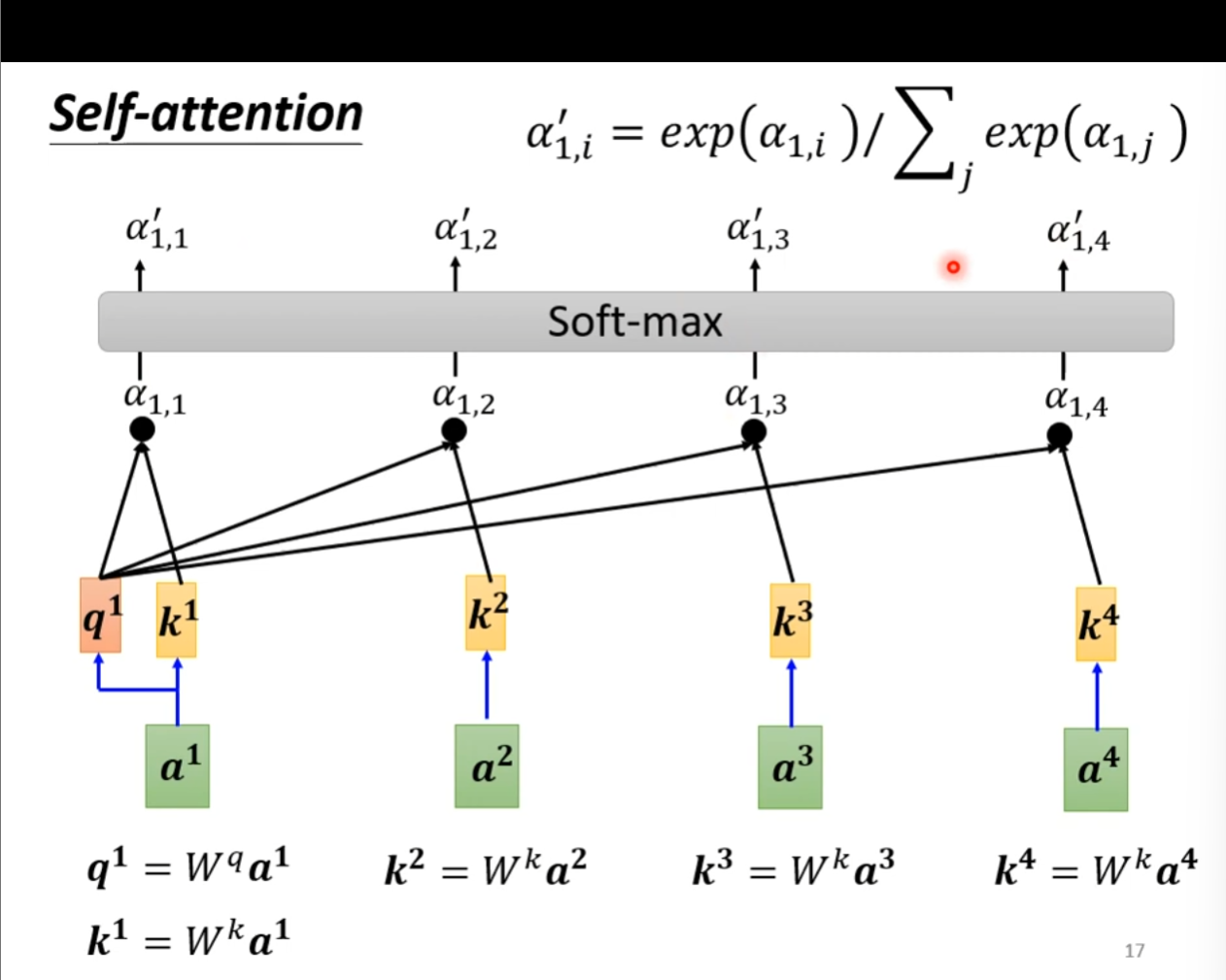
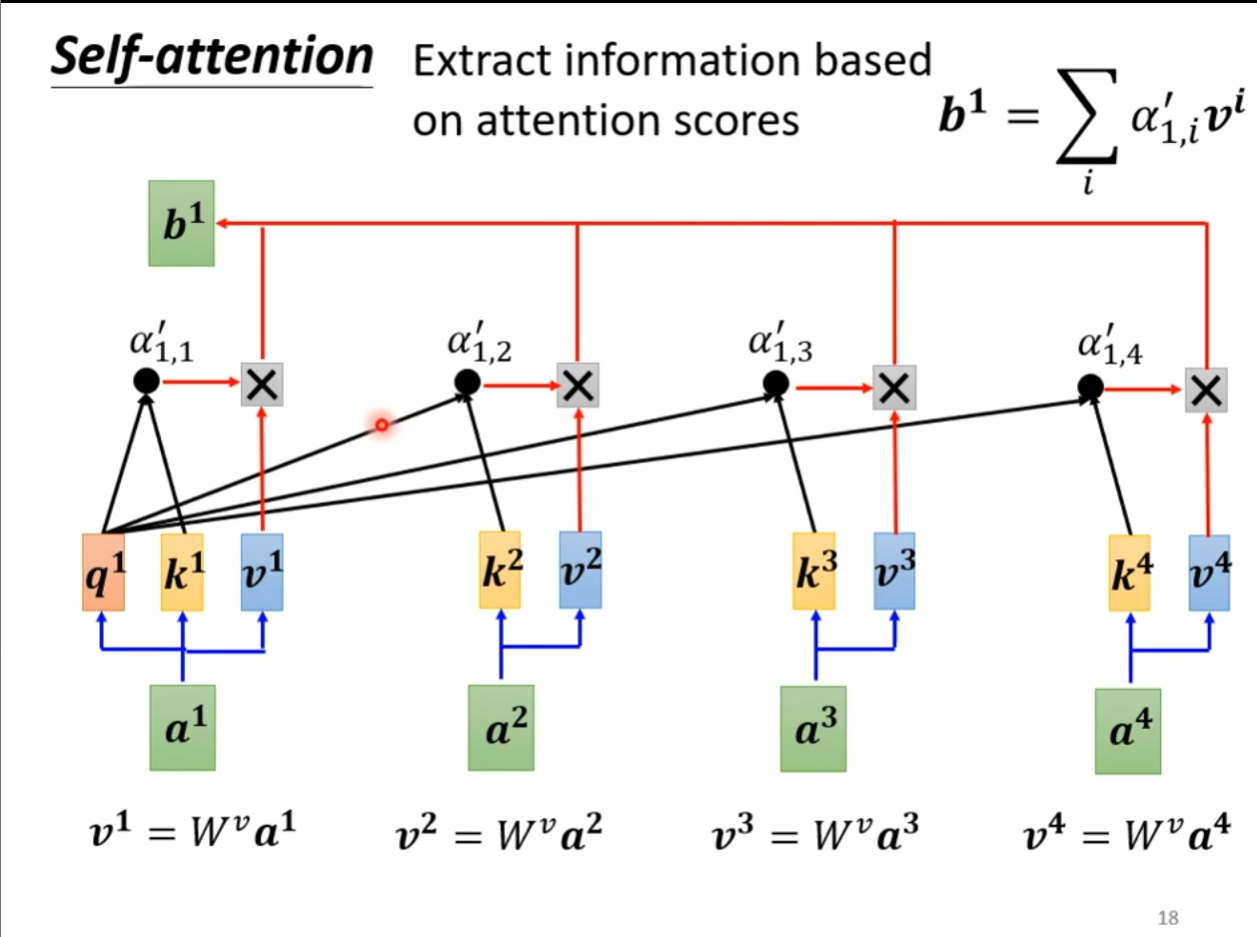
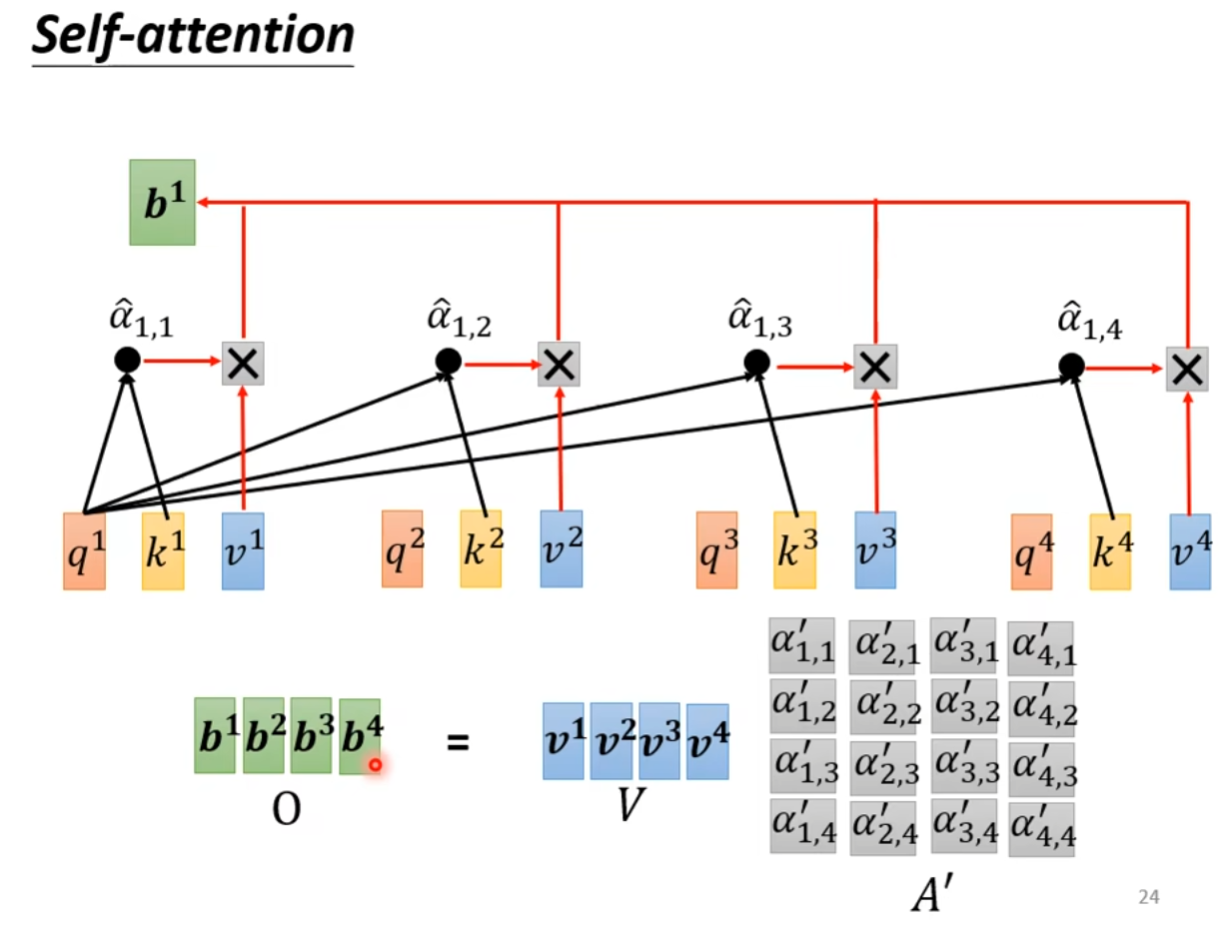
自注意力机制 (Self-attention)
- 找到与
相关的向量,用 表示相关向量 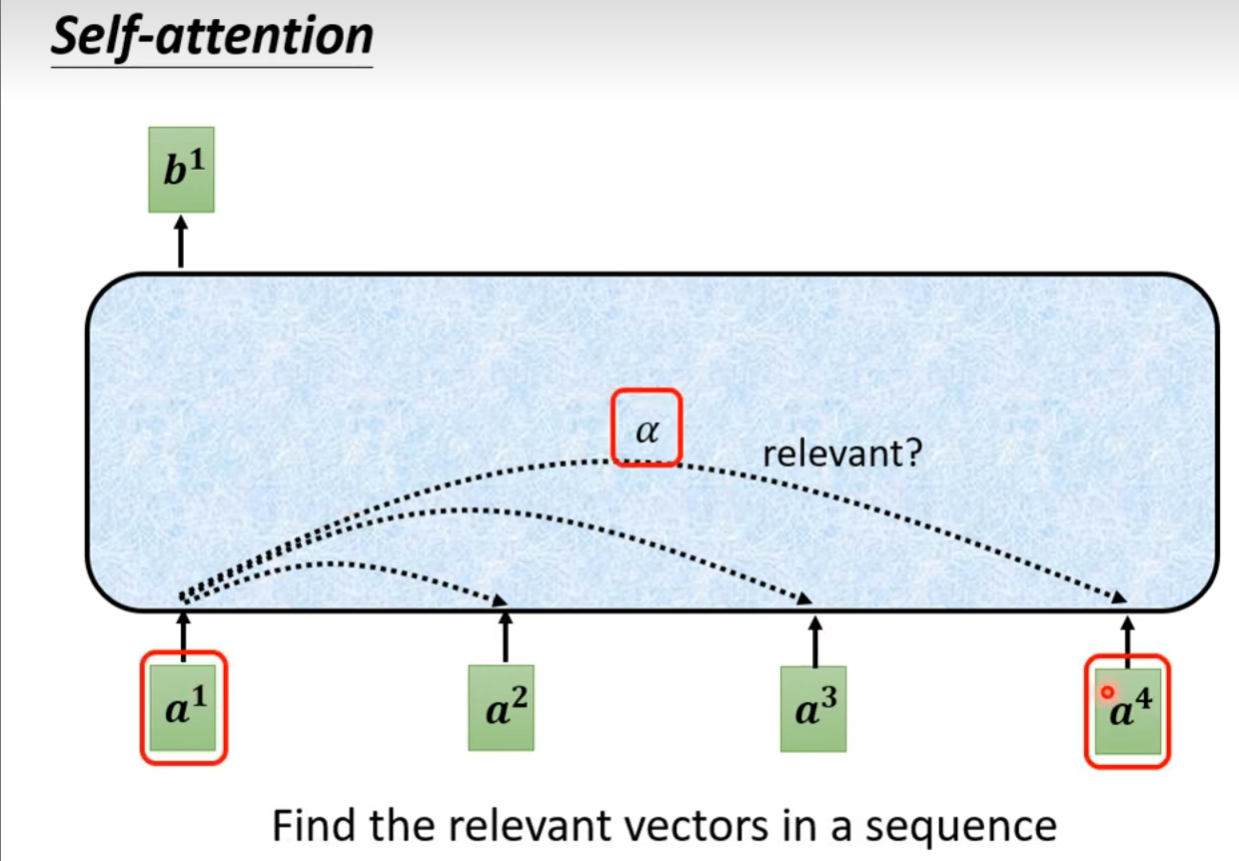
- 使用点积 (Dot-product) 和加法 (Additive) 来计算
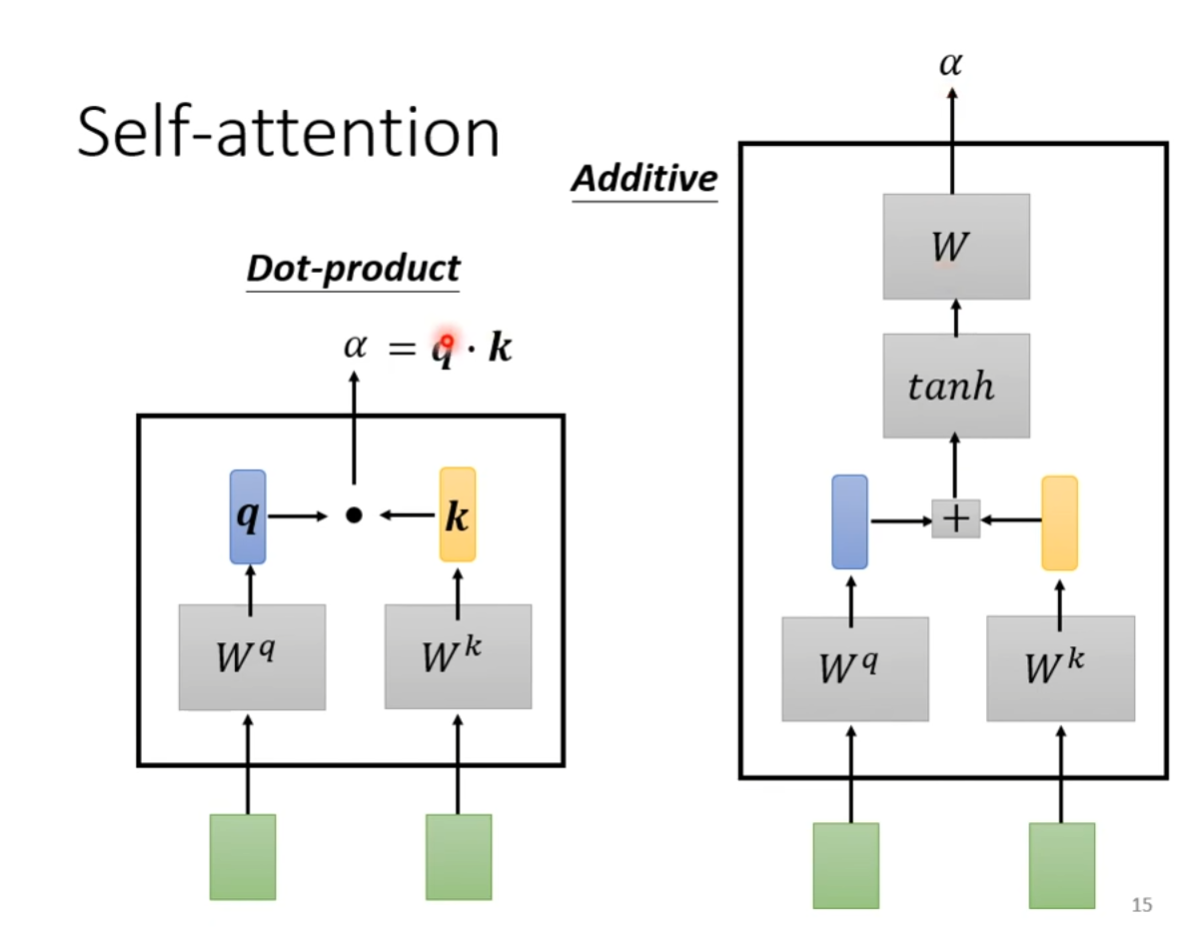
- 也可以使用其他函数如 ReLU
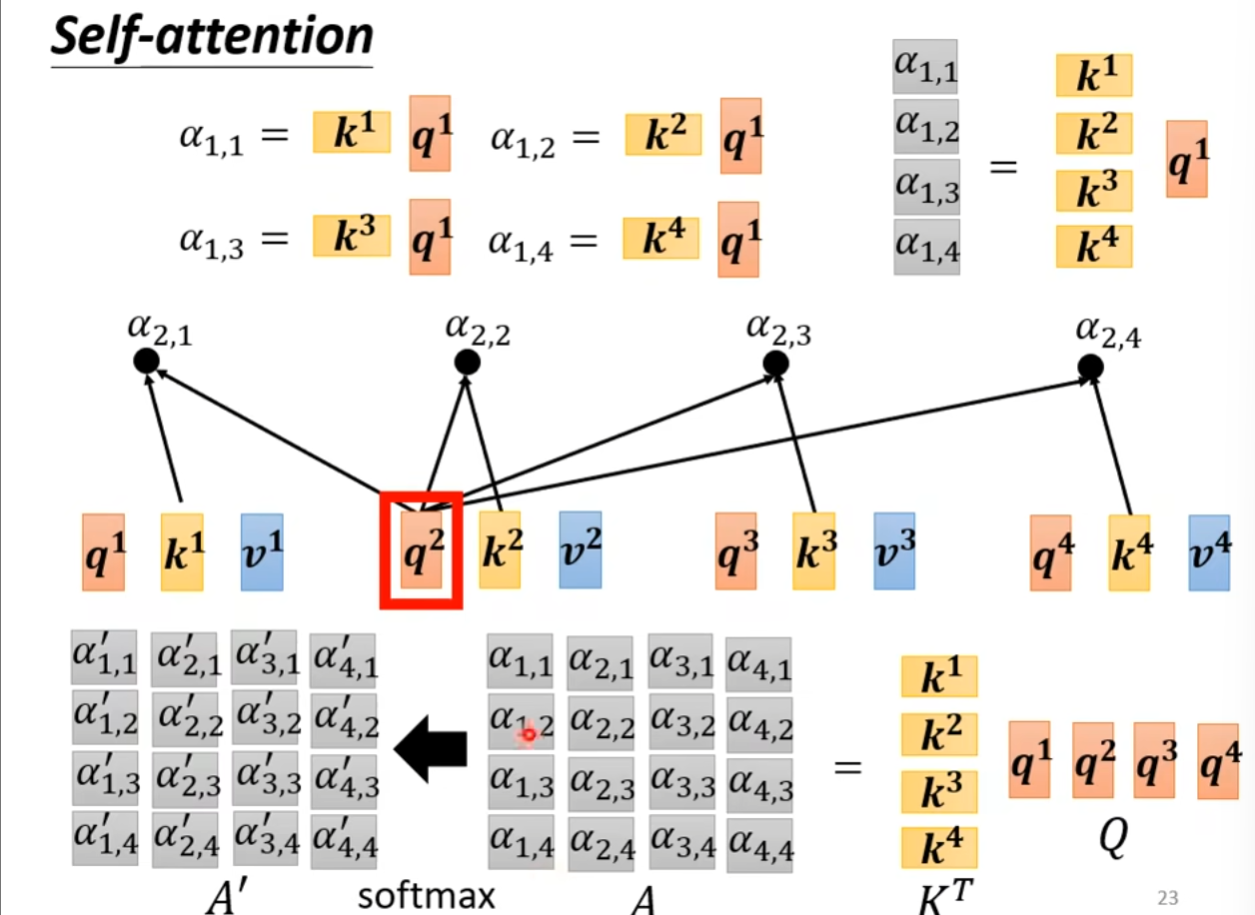
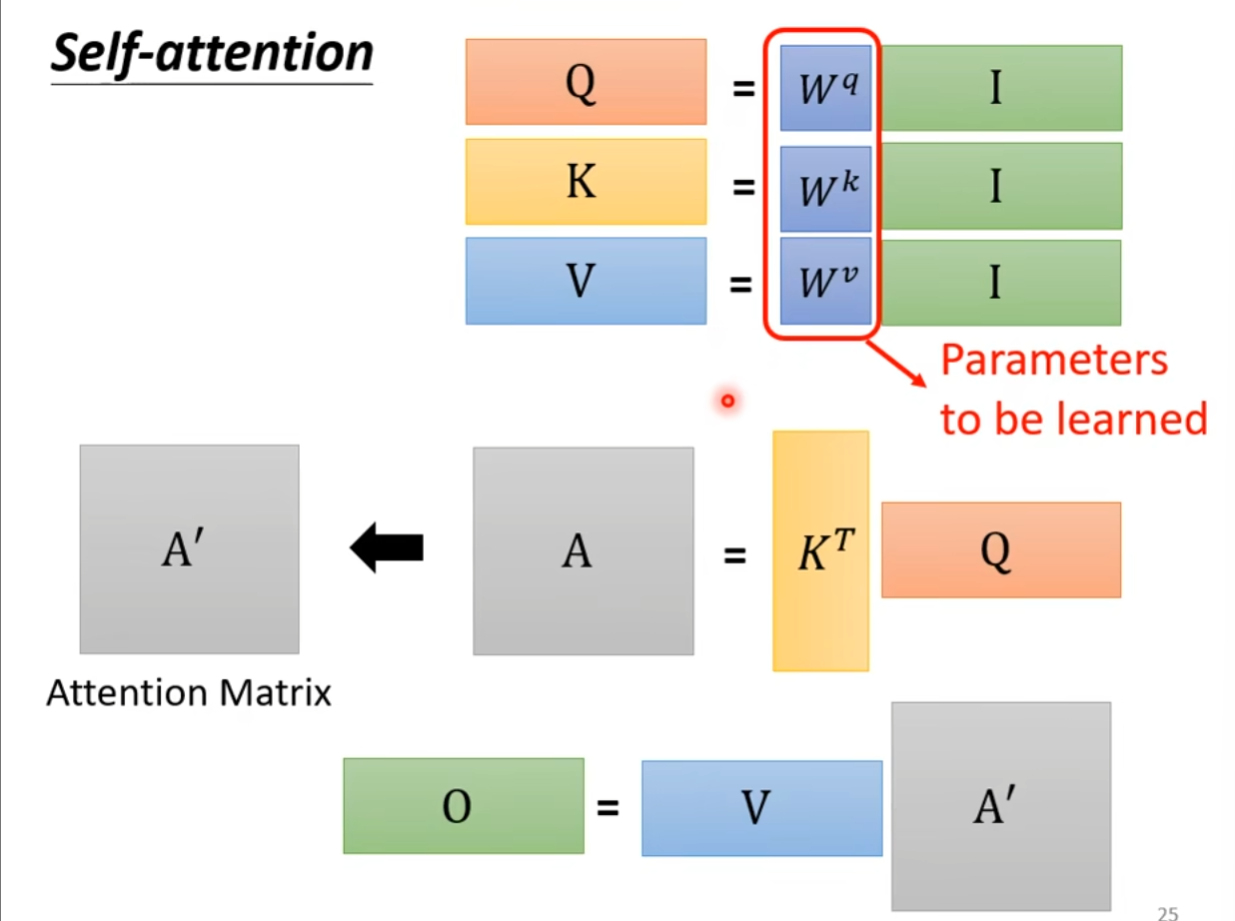
矩阵描述
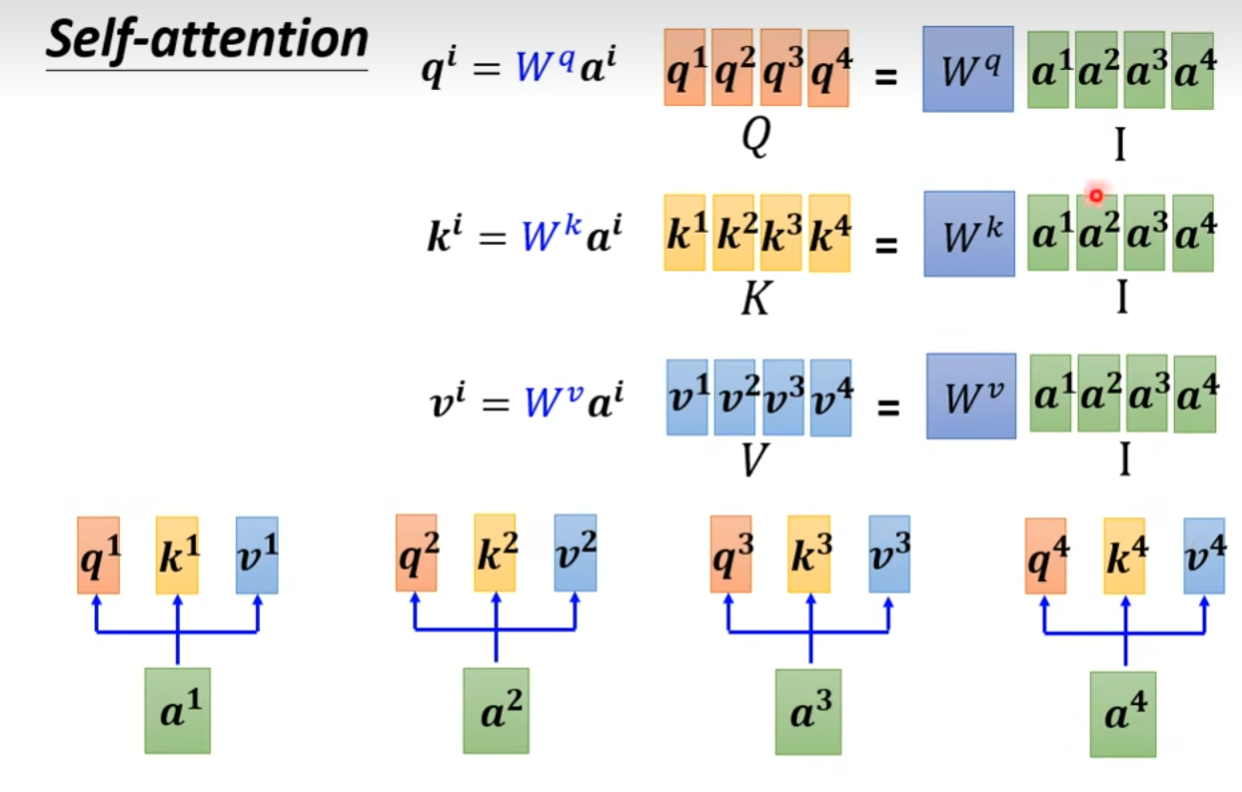 [
[  
Multi-head Self attention
、 代表了不同的关系类型 - 每一种关系类型只和自己相同的关系类型做操作,例如
的产生中,所使用的矩阵均为
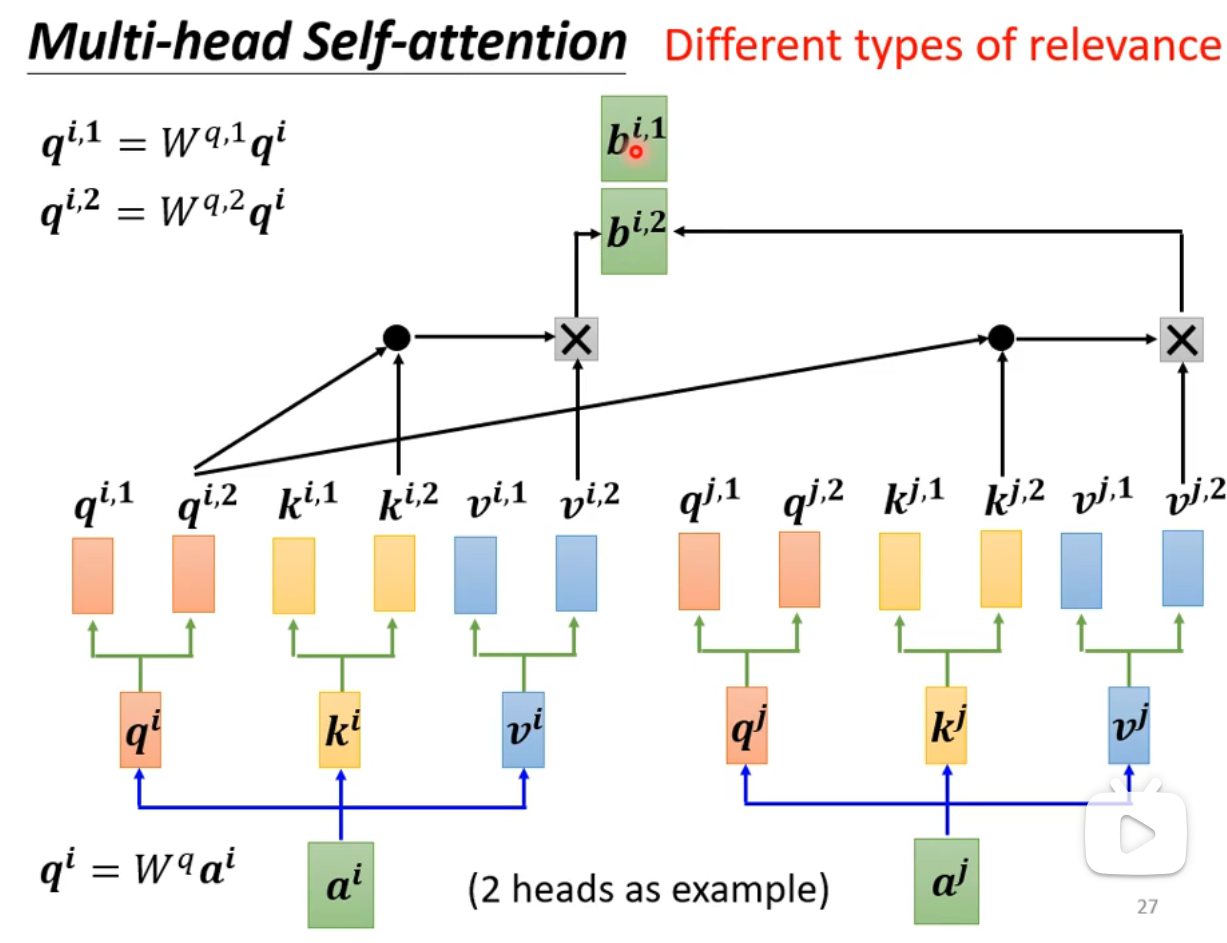 - 最后拼接
- 最后拼接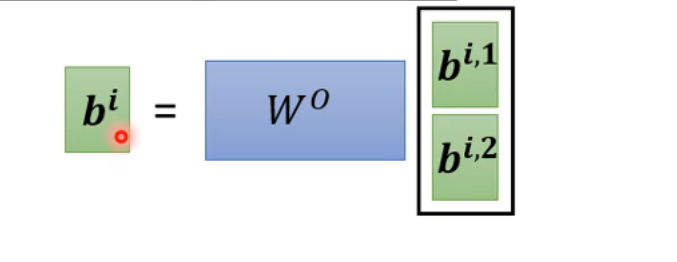 ## Positional Encoding - 对self-attention而言,没有体现出位置信息,即使
## Positional Encoding - 对self-attention而言,没有体现出位置信息,即使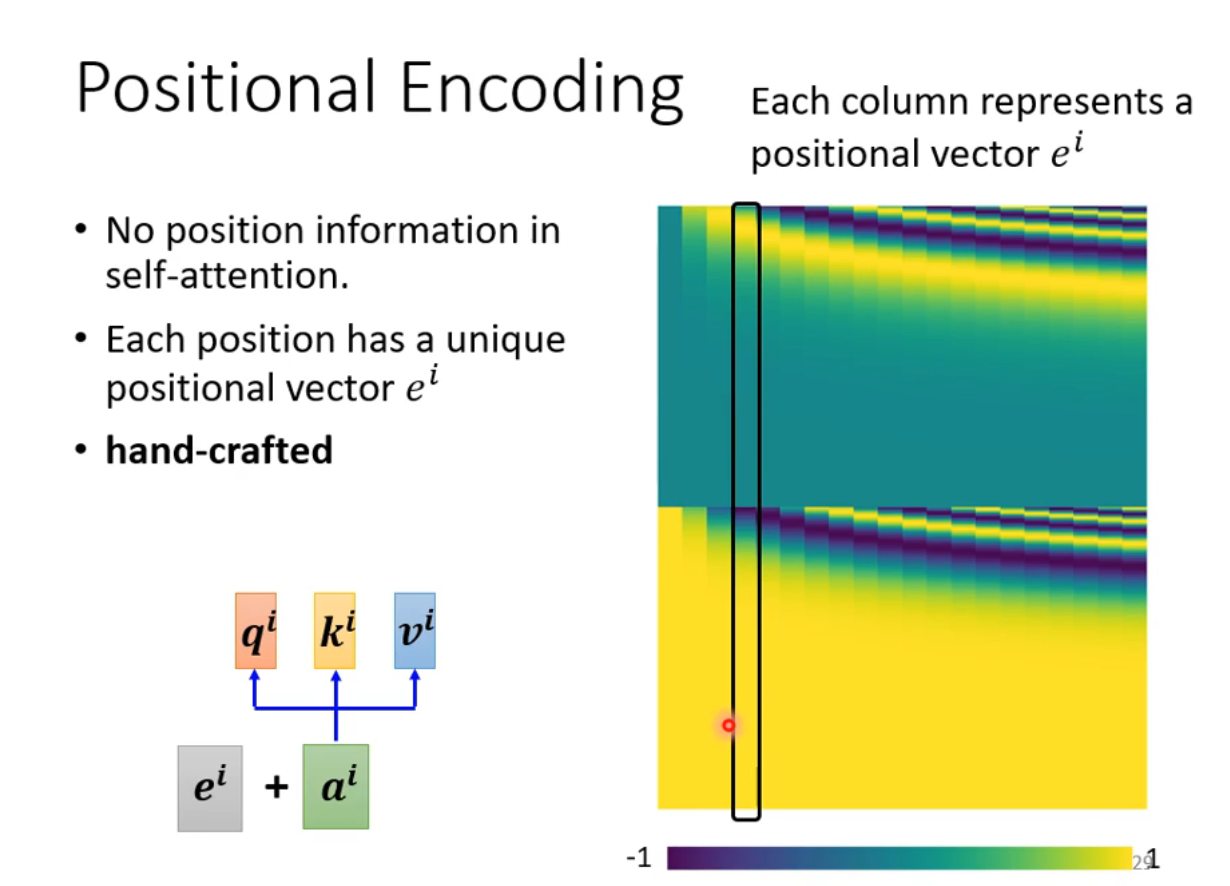 - Positional Encoding依然是一个尚待研究的问题 ## Self-attention for Speech - 语音序列一般比较长,如果语音序列的长度为
- Positional Encoding依然是一个尚待研究的问题 ## Self-attention for Speech - 语音序列一般比较长,如果语音序列的长度为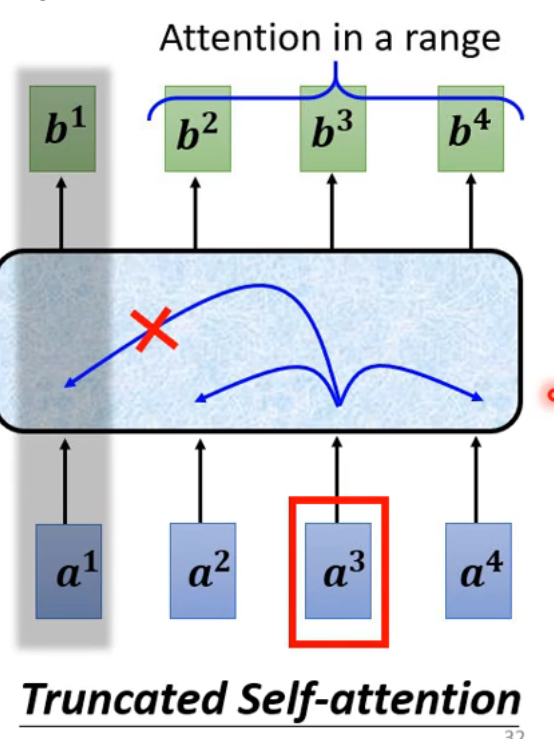 ## Self-attention for Image - 将不同的通道的像素组合看做一个向量
## Self-attention for Image - 将不同的通道的像素组合看做一个向量 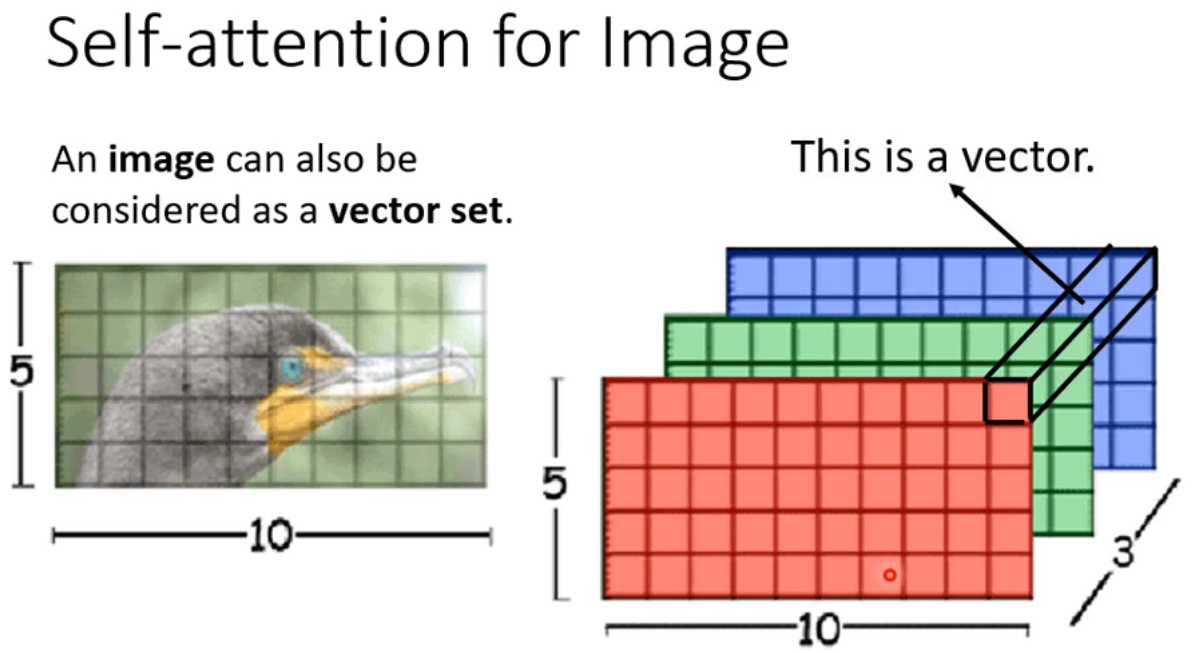
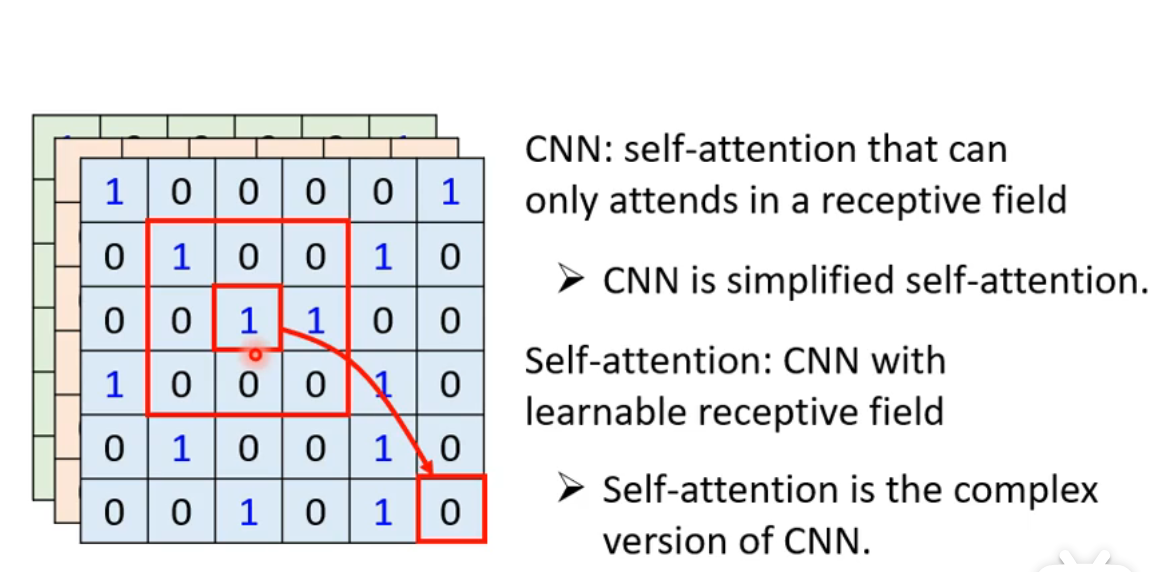
Self-attention vs CNN
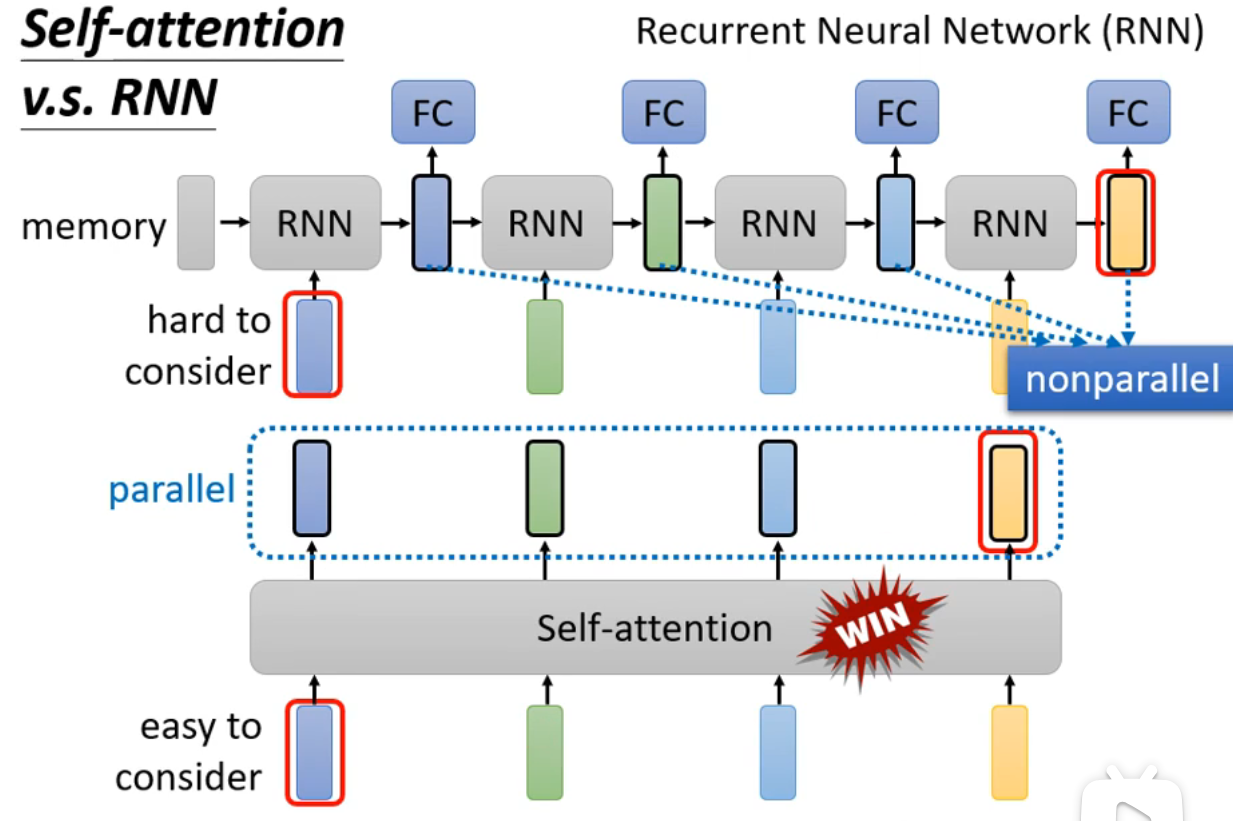
Self-attention vs RNN
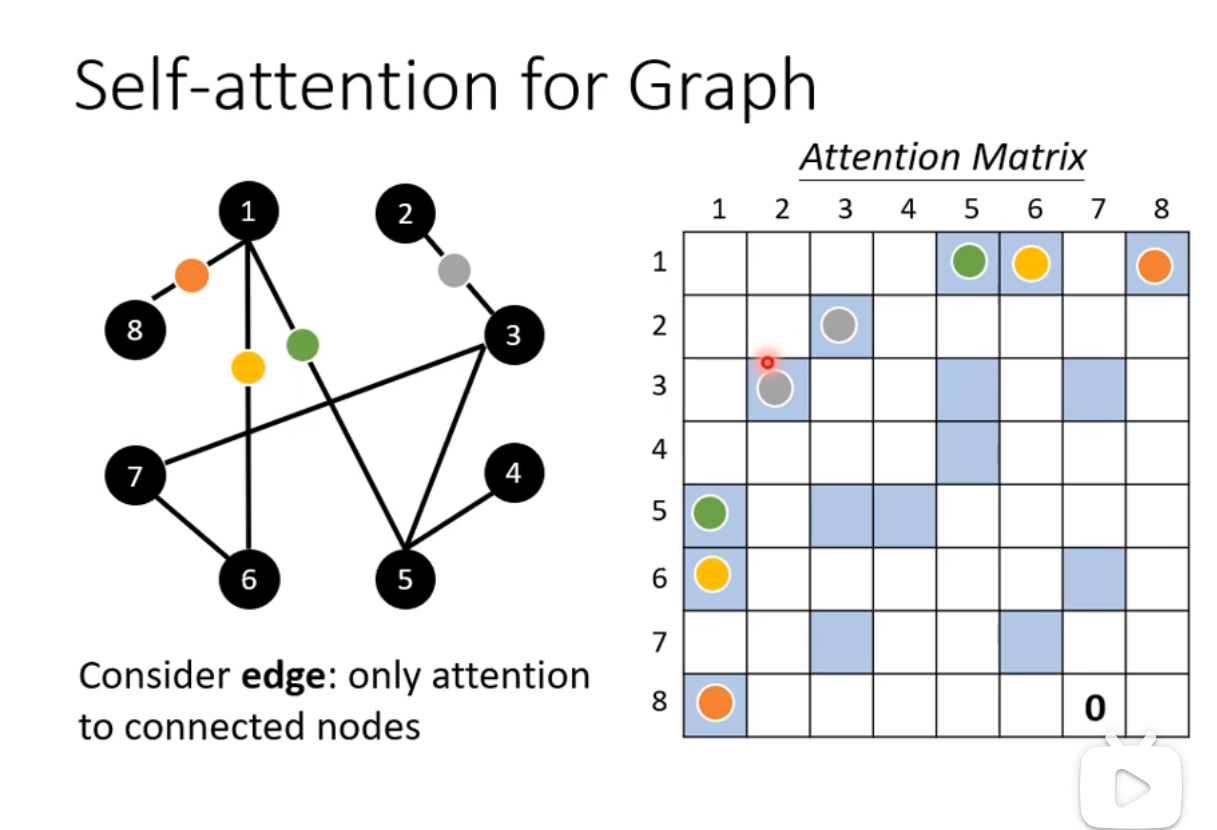
Self-attention for Graph