介绍各种各样的自注意力机制
[!NOTE] Notice Self-attention 往往只是一个network中的一个小模块,当input序列长度很长时,Self-attention的计算量很惊人,以至于成为整个模型的主要计算开销。
Local Attention/Truncated Attention
attention矩阵并非必须要全部计算,有一些值可以根据对任务的理解预设。
例如,有时对于一个序列,我们并非需要知道整个距离的attention,而只需要关注左右邻居,所以我们可以将除开左右邻居的所有attention weight设为0。 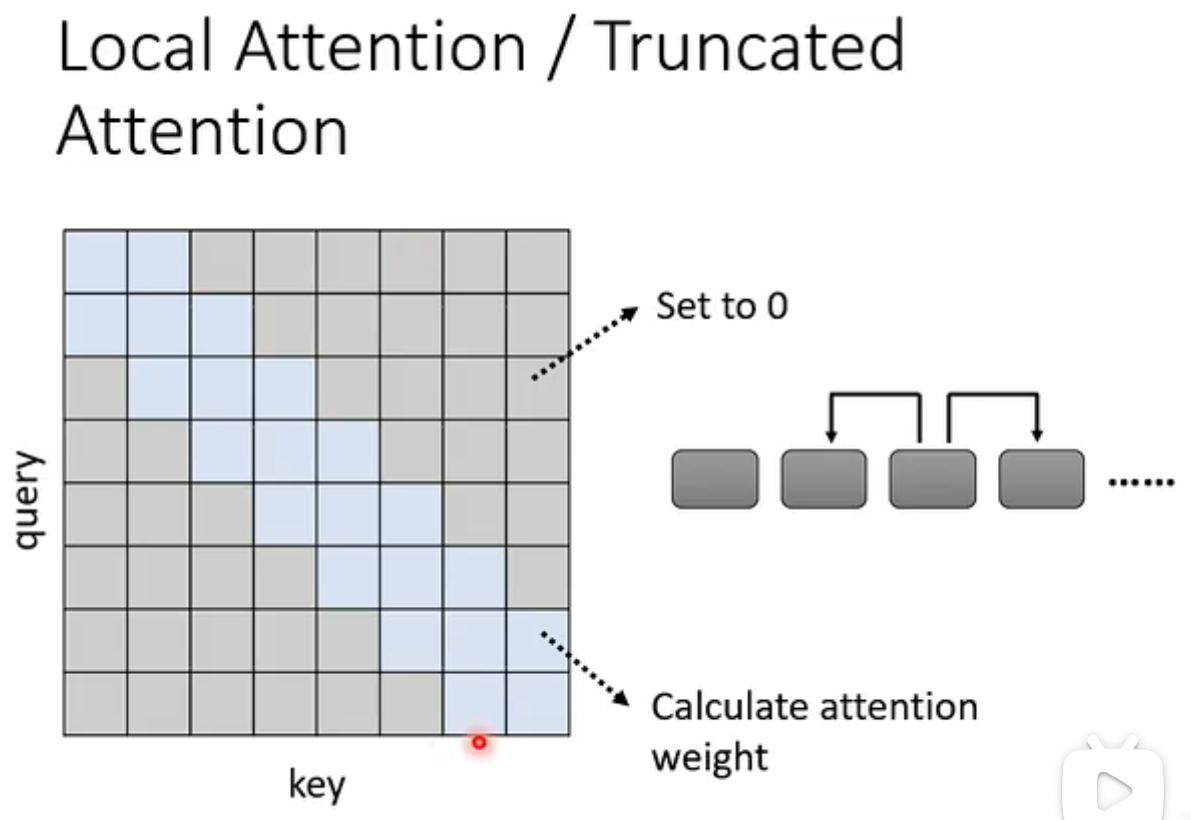 由于只看见了小范围的咨讯,所以这样做的self-Attention和CNN很相似了。 ## Stride Attention 设置一个stride,看远距离的几个邻居
由于只看见了小范围的咨讯,所以这样做的self-Attention和CNN很相似了。 ## Stride Attention 设置一个stride,看远距离的几个邻居 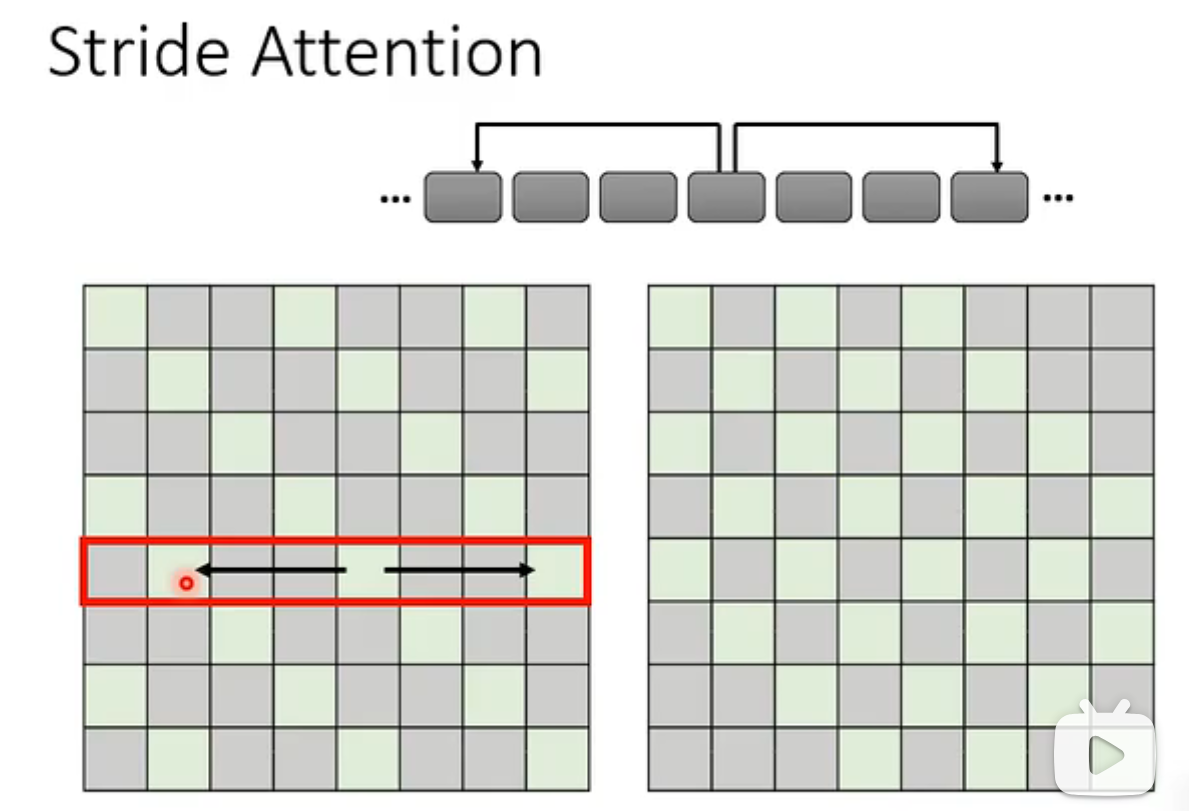 ## GLobal Attention 在原始的序列中加入一个特殊的符号,这个符号的作用:
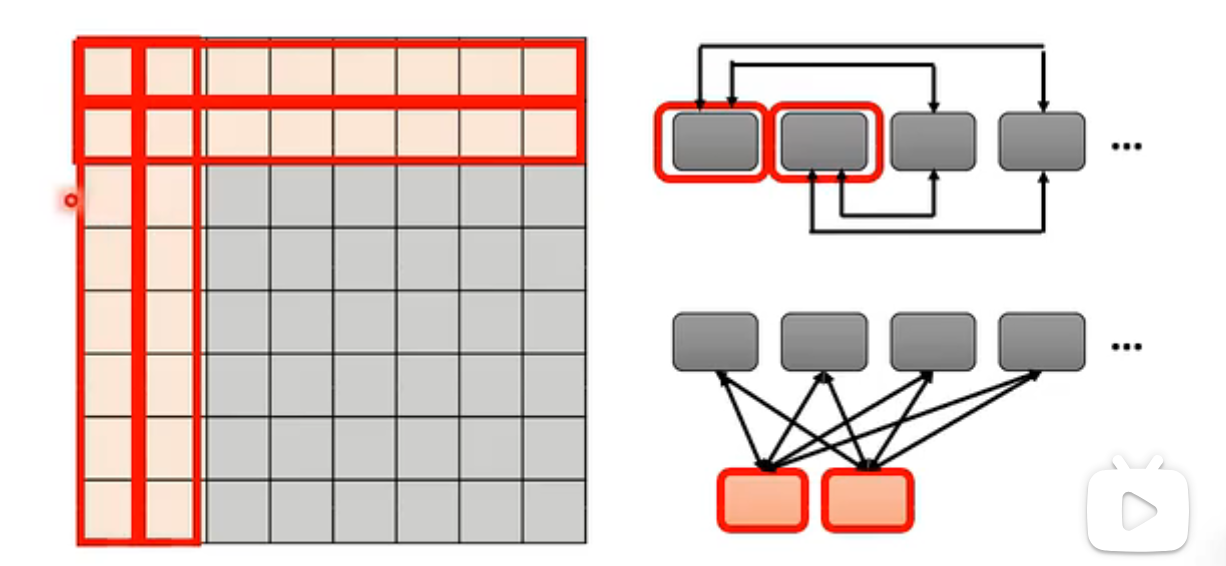
## GLobal Attention 在原始的序列中加入一个特殊的符号,这个符号的作用:
- Attend to every token
collect global information - Attended by every token
it knows global information
两种加入特殊token的做法:
- 在原始序列中选择一个token,例如开始符号cls或者句号等等
- 外加token,下图的例子使用的token是句子的前两个token,特殊token和其他所有token对应的key都做了dot product,而non-special token之间没有attention。
[!NOTE] Best in practice Different attention in different heads! ## Focus on Critical Parts
We want to use data-driven methods instead of manual operations. In an attention matrix, the values of critical parts should be large, while small values in other parts (such as setting them directly to 0) will reduce their influence on the results. So, the question becomes: how can we quickly estimate portions with small attention weights? 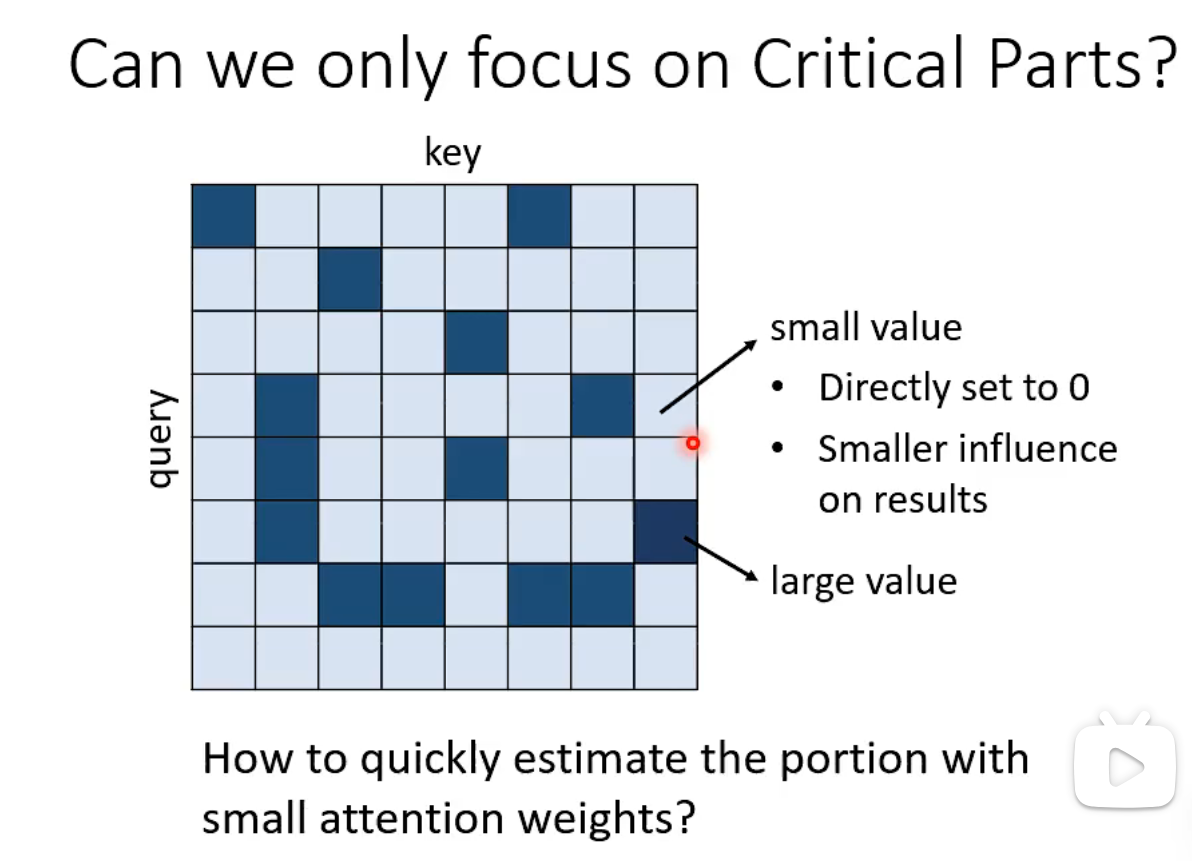
Clustering
Both Reformer and Routing Transformer use clustering to address the above issue. - Step 1: Cluster the query and key based on similarity. Keys and queries in the same cluster will be calculated later. Clustering methods can be approximate and fast.
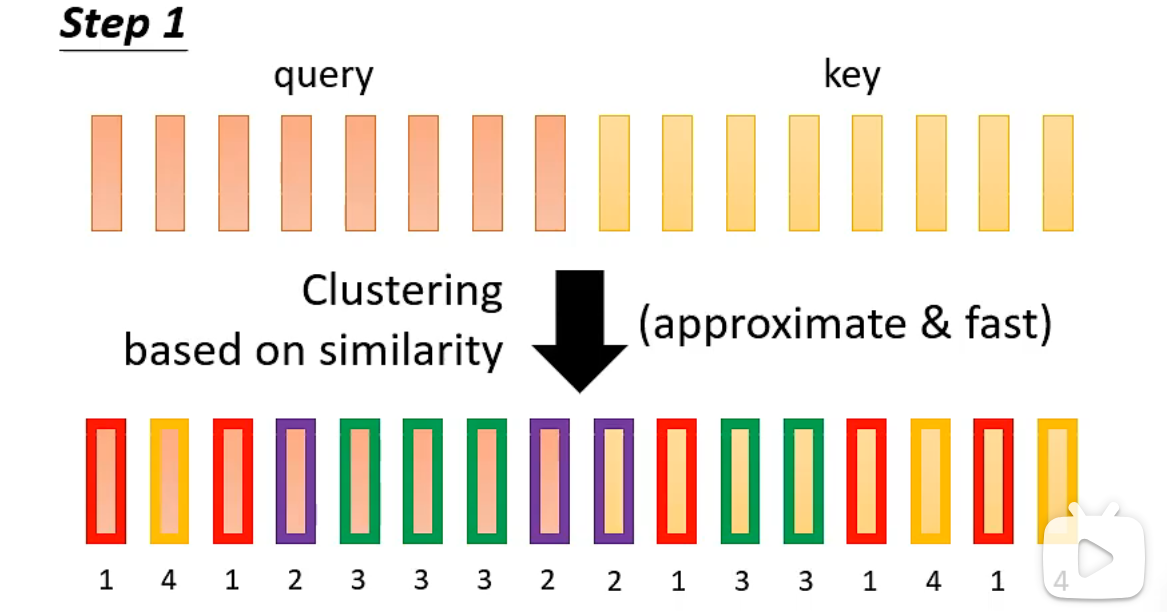
- Step 2: Only keys and queries in the same cluster will be used to calculate attention weights; otherwise, the attention weight is set to 0.
Learnable Patterns
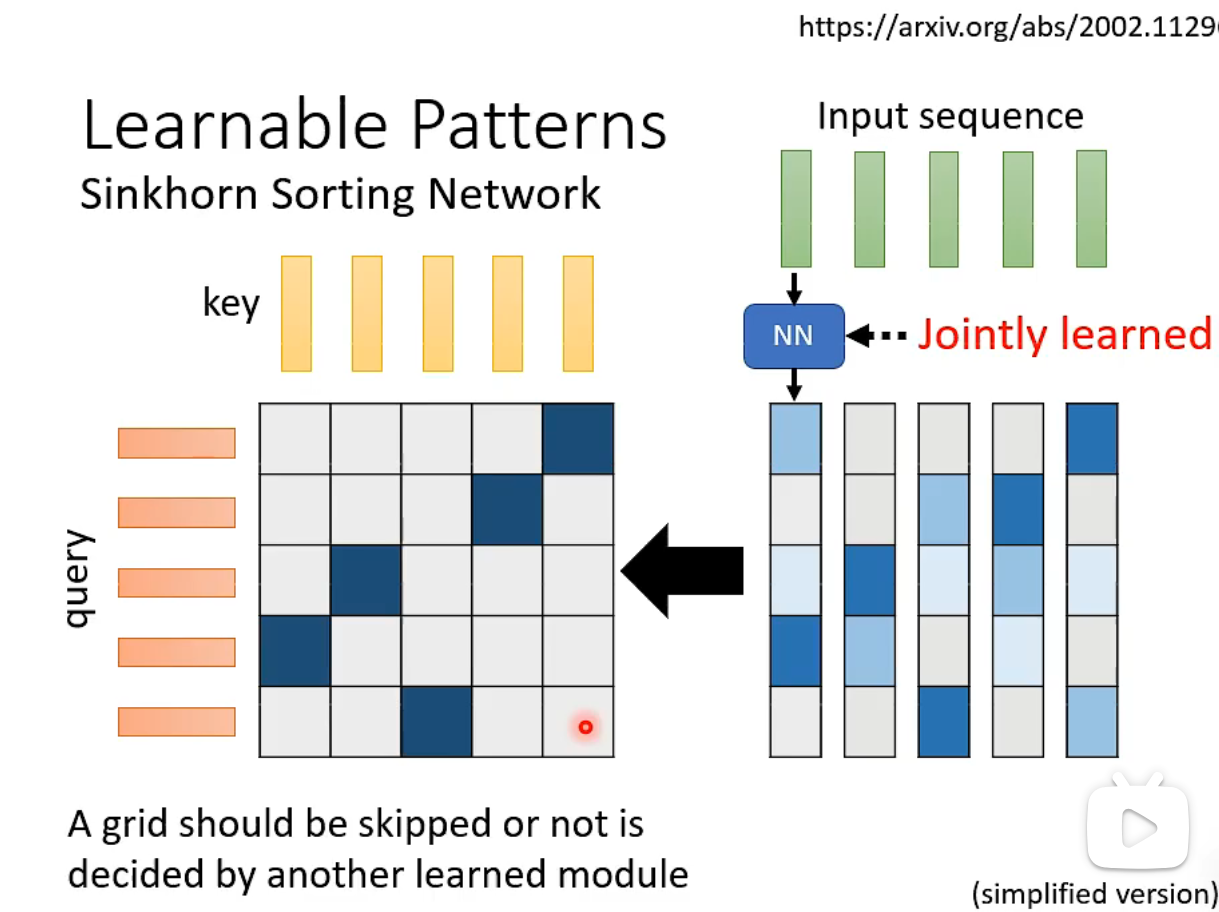
Sinkhorn Sorting Network uses a learned module to decide if a grid should be skipped or not.
The matrix on the left contains binary values. The input sequence is passed through a neural network that generates vectors (each vector has the same length as the input sequence).
A critical part of the network is that it makes the matrix on the right, a non-binary one, similar to the matrix on the left. The process is differentiable.
Do We Need the Full Attention Matrix?
Linformer proposed that the attention matrix tends to be low-rank and contains many redundant columns, which makes computation inefficient. 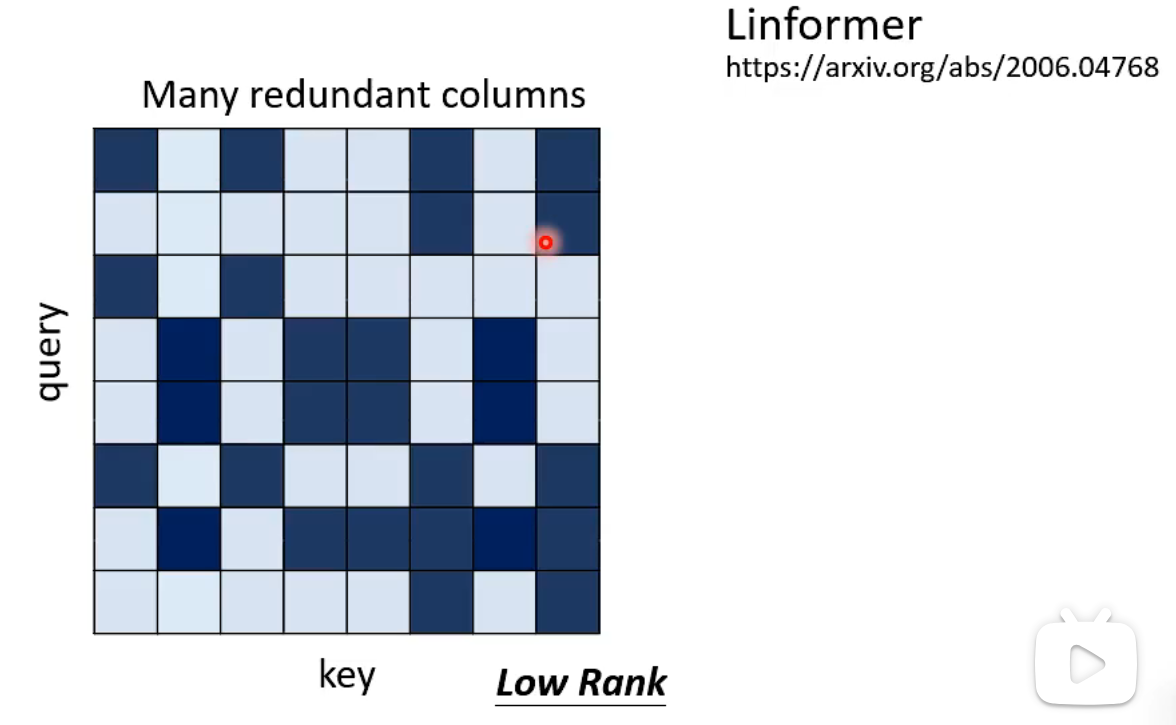
Choose Representative Keys
To construct the attention matrix, we choose representative keys. Additionally, we need to select representative vectors to obtain the outputs of self-attention.
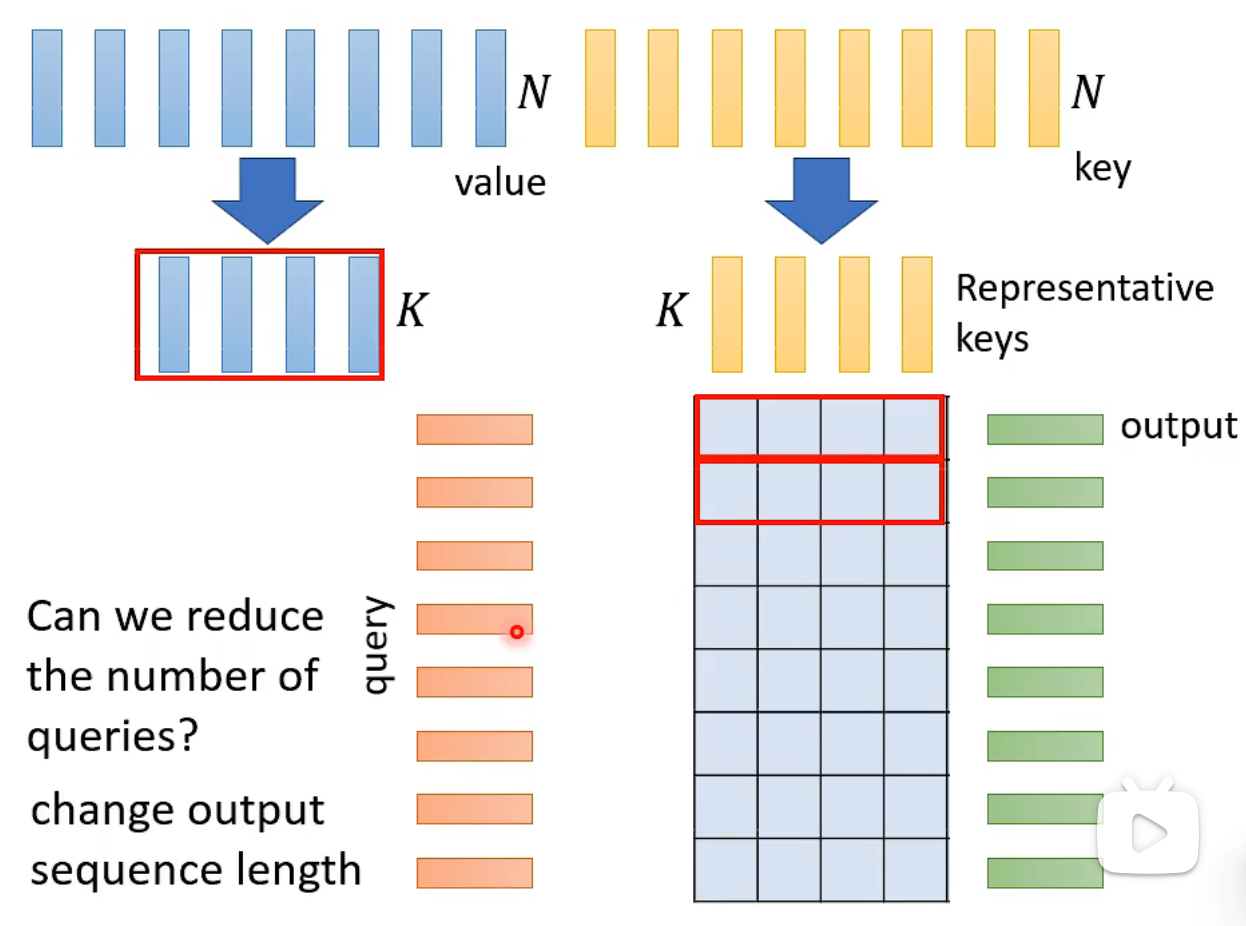
However, a question arises: Can we reduce the number of queries? This generally depends on the task. For sequence-to-label tasks, reducing the number of queries might be acceptable, as not all queries are needed to make predictions. But if we need to label every position in the query, such as assigning phoneme labels to each frame, reducing the number of queries will likely result in incorrect predictions.
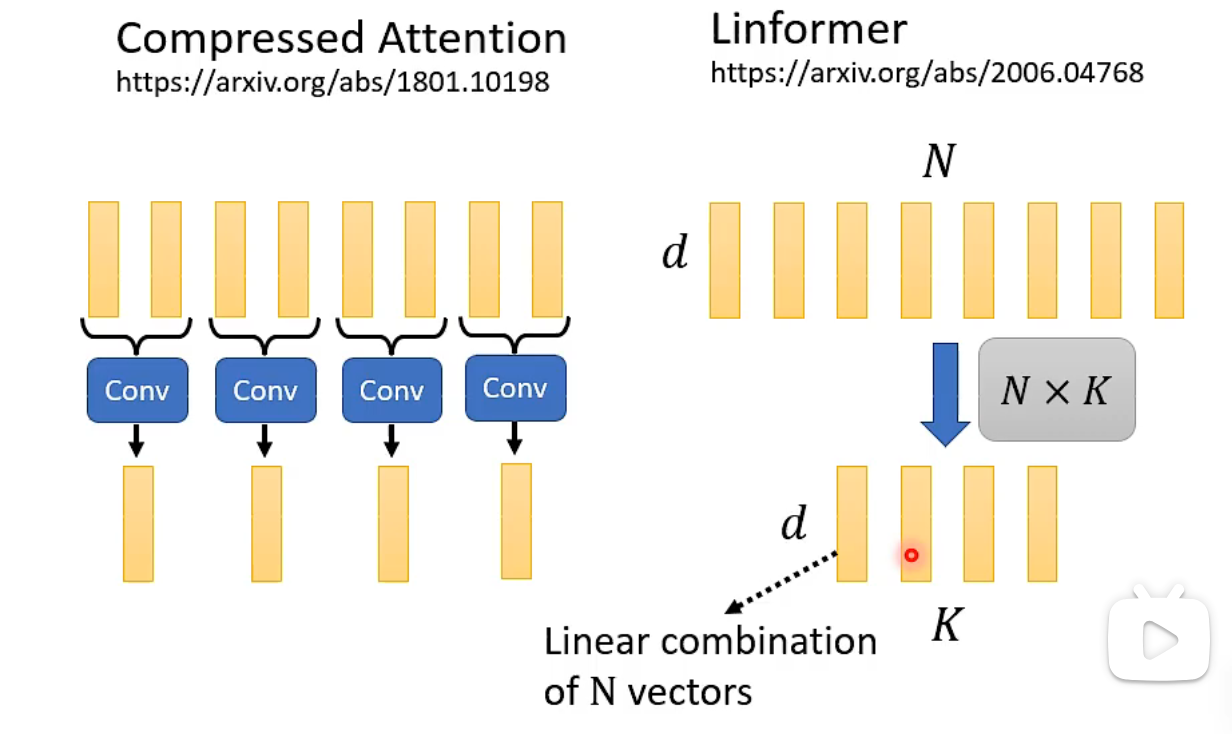
How to Reduce the Number of Keys
Compressed Attention uses convolution for subsampling, while Linformer uses
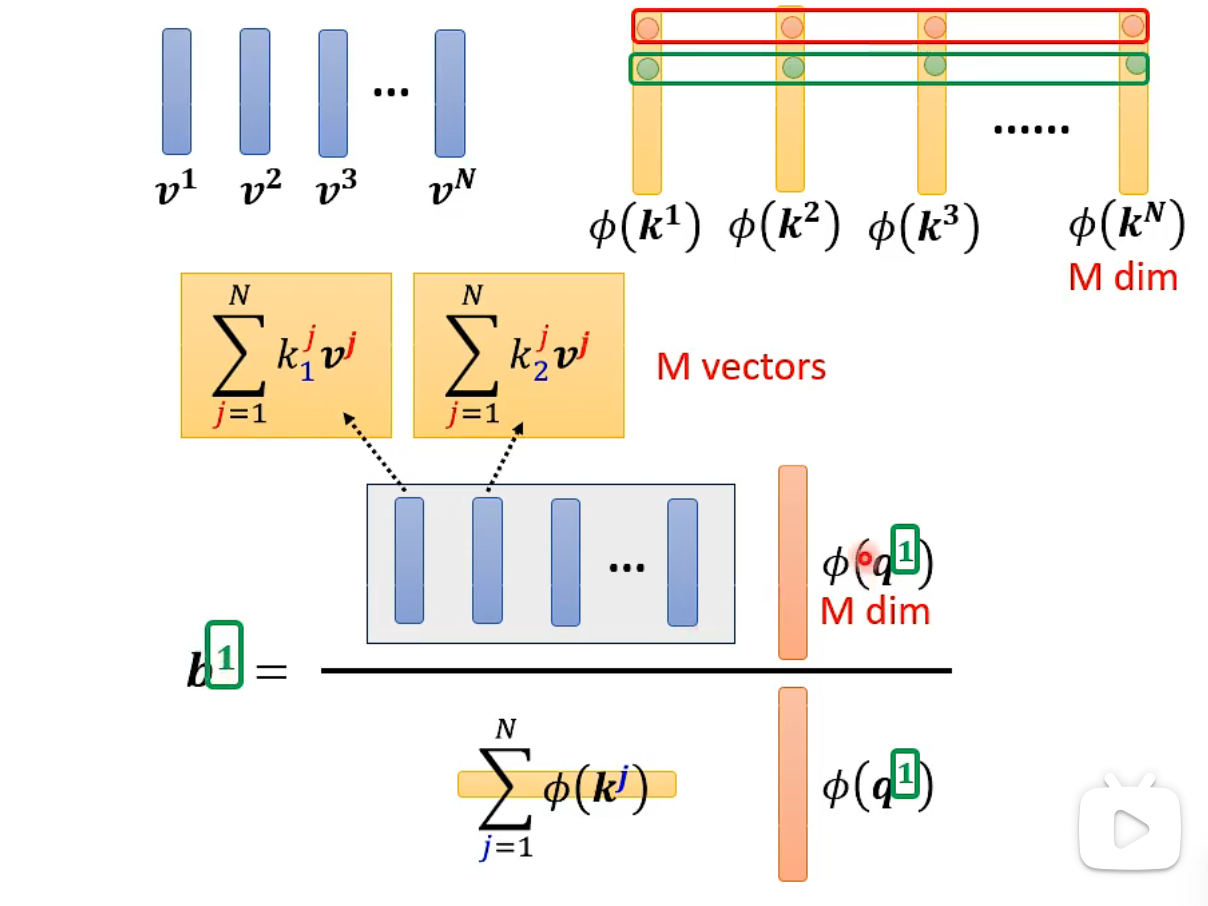
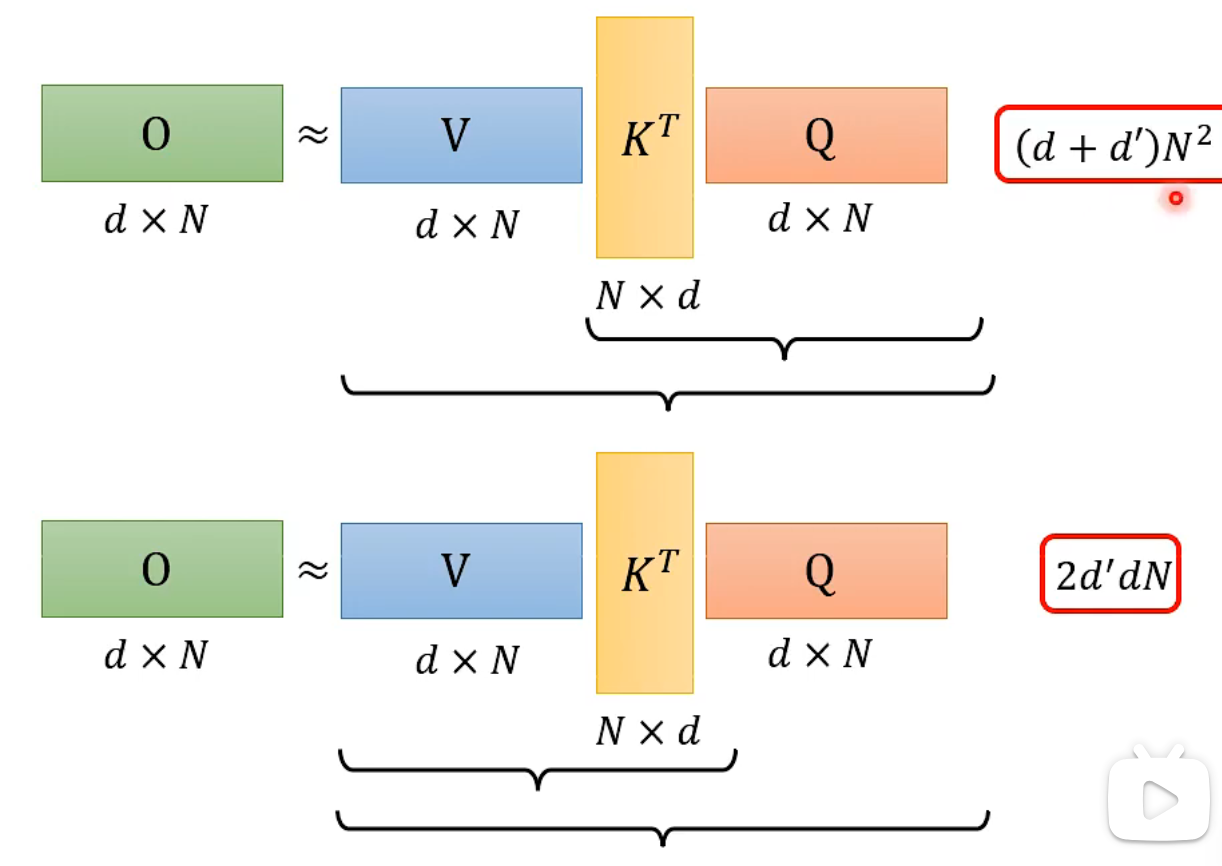
However, numerous matrix operations can be costly. We can reduce the operation cost by changing the order of operations.
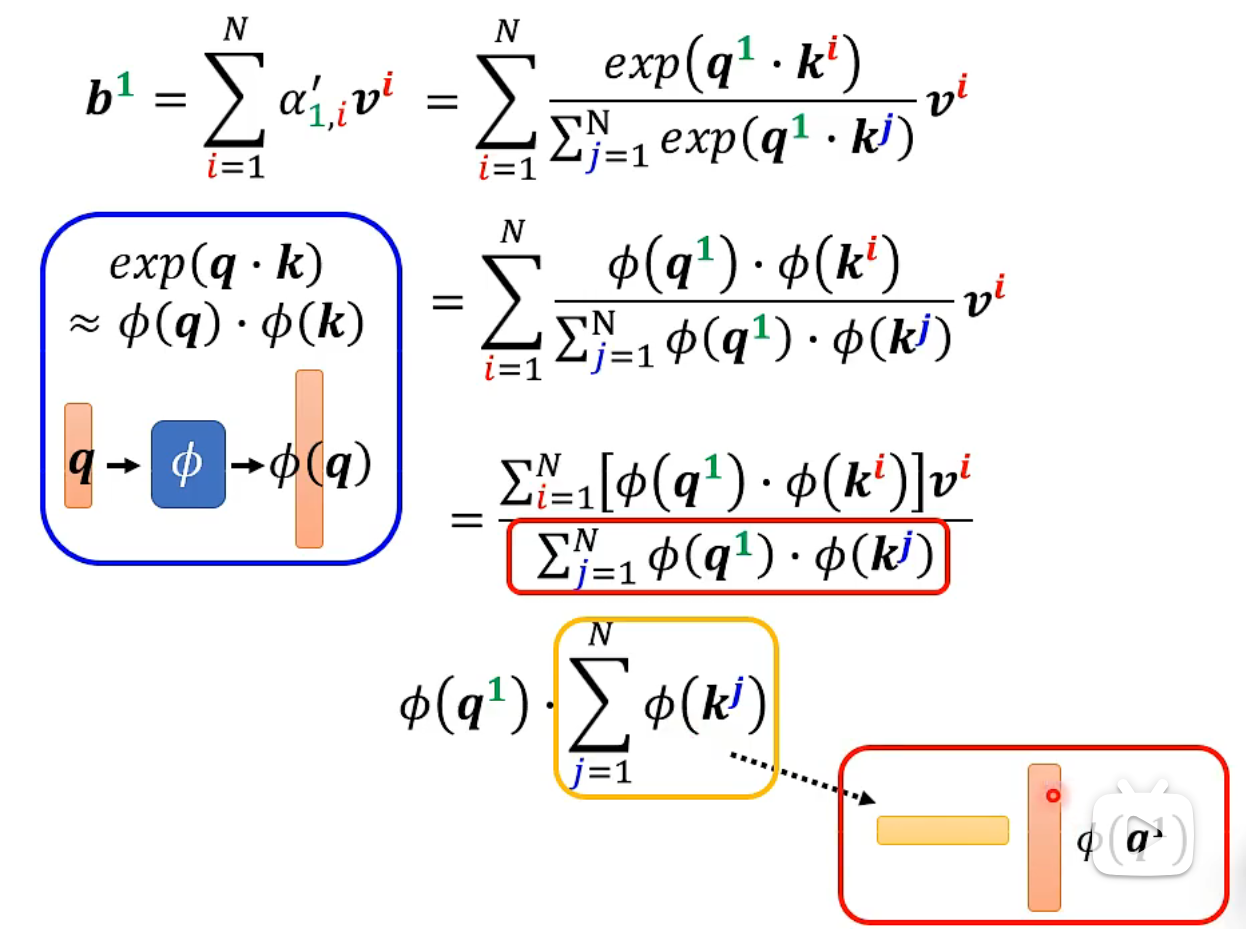
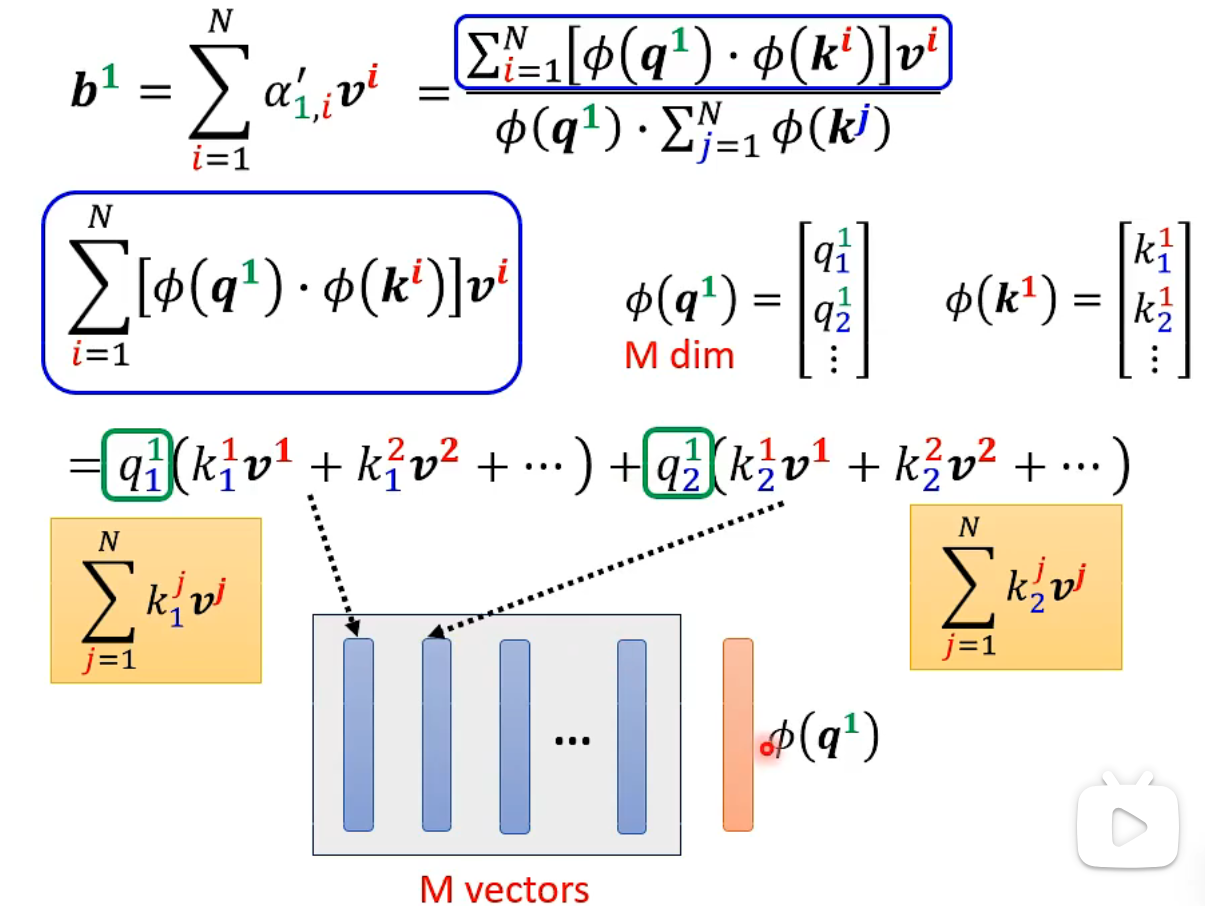
The softmax process can generally be described as follows (a comprehensive and complex computation process will be introduced later). Pay attention to the blue and yellow vectors, which are not related to the annotation
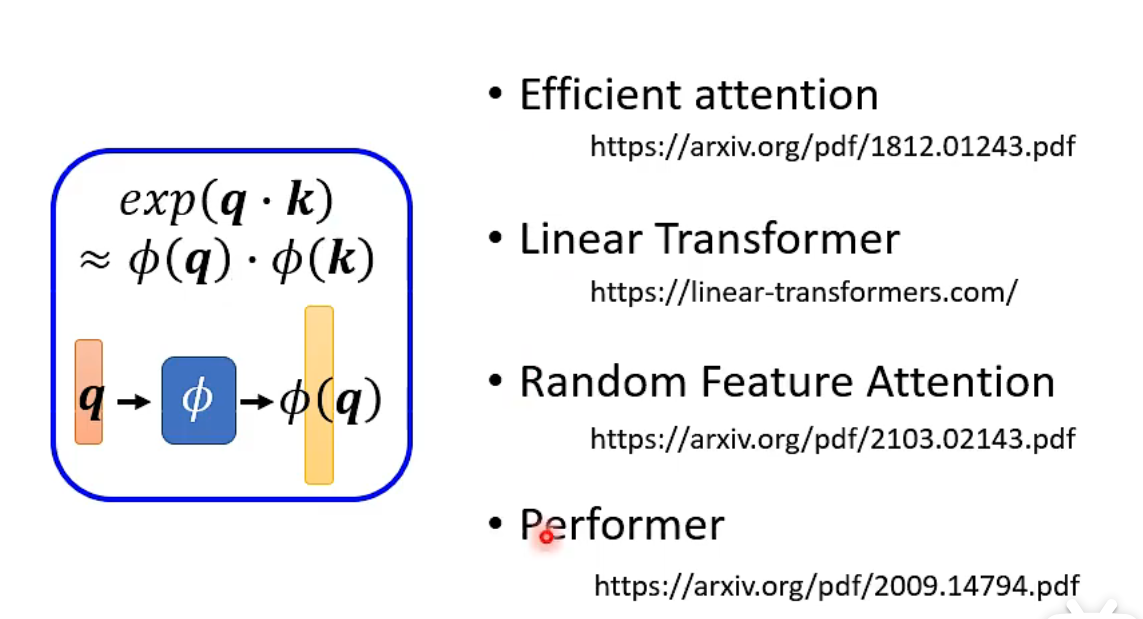
These papers show how to obtain the
- Full computation process:
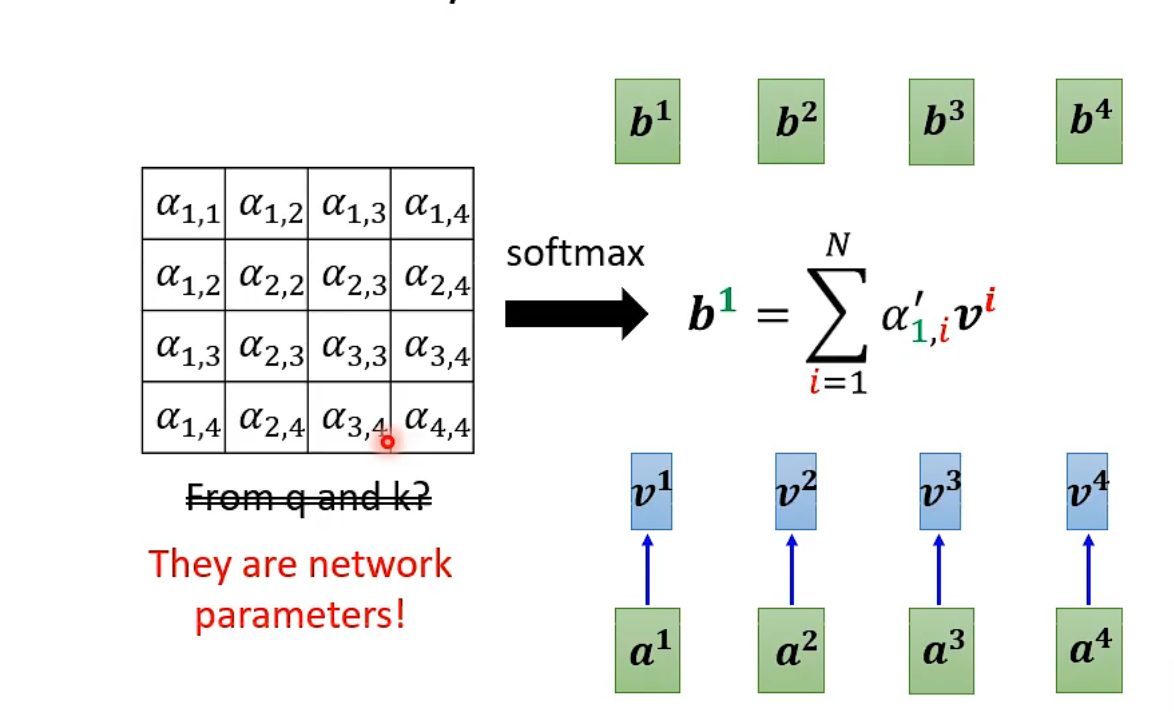
Do We Need q and k to Compute Attention? Synthesizer!
In Synthesizer, we don't compute attention scores from q and k; instead, we regard the attention matrix as network parameters.
Now we need to rethink the meaning of self-attention…