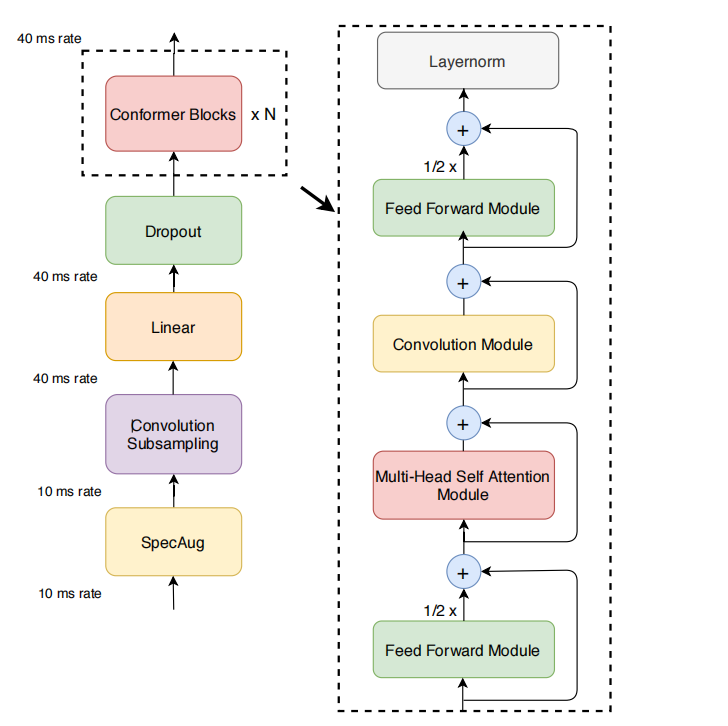
本文记录阅读Conformer的笔记,以此来达成李宏毅2022深度学习HW4的strong line ## 论文阅读 ### 背景 - transformer:擅长捕捉内容层面的 全局依赖,即长时间范围的上下文信息。 - CNN 模型:善于提取 局部特征,比如音频信号的局部变化。 ### Conformer Encoder #### 1. 音频编码器的结构
- 输入处理:模型首先通过一个 卷积子采样层(convolution subsampling layer) 处理输入。这一层用于对输入进行下采样,减少输入数据的尺寸,同时保留重要的局部特征。这一步骤常用于音频处理,以降低计算量并提取高效的特征。
- Conformer块:接下来,输入会通过多个 Conformer块(Conformer blocks) 进行处理。Conformer块 是该模型的核心组成部分,是替代传统 Transformer块 的创新设计。 #### 2. Conformer块的组成
每个 Conformer块 包含四个主要模块,它们按顺序堆叠在一起:
前馈模块(Feed-forward module):处理输入的全连接网络部分,通常用于非线性映射。
自注意力模块(Self-attention module):这是Conformer的关键,采用自注意力机制来建模序列中各个位置之间的依赖关系,捕捉全局信息。
卷积模块(Convolution module):用于捕捉局部特征,卷积操作能够有效提取输入中的局部模式,增强模型对局部信息的敏感性。
第二个前馈模块(Second feed-forward module):该模块位于最后,通常用于进一步的特征变换或增强表达能力。
 ### Muti-head-self-attention with relative positional embedding
### Muti-head-self-attention with relative positional embedding 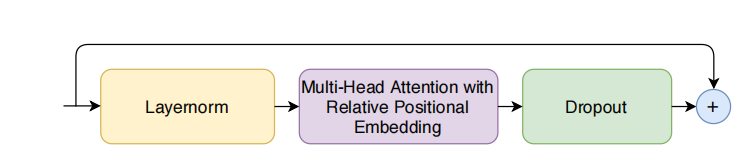 #### 1. 多头自注意力(Multi-Headed Self-Attention,MHSA)
#### 1. 多头自注意力(Multi-Headed Self-Attention,MHSA)多头自注意力 是 Transformer 模型中的一个核心组件。在 Conformer 中,使用了这种机制来捕捉输入序列中不同位置之间的依赖关系。
多头 指的是将注意力机制分成多个 "头",每个头独立地关注输入序列的不同部分,然后将这些注意力头的结果拼接在一起,提供更丰富的表示。
2. 相对位置编码(Relative Positional Encoding)
- 相对位置编码 是 Transformer-XL 中提出的一种技术,Conformer 也采用了这种技术来改进自注意力模块。
- 传统的 绝对位置编码 使用固定的编码表示每个位置,限制了模型在处理变长输入时的灵活性。相对位置编码通过考虑两个位置之间的相对距离,而不是固定的位置编码,使得模型能够更好地处理不同长度的输入。这使得 Conformer 在变长语音输入(如语音识别任务中)的表现更加稳健,能够适应不同长度的句子或语音片段。
3. Transformer-XL中的技术
Transformer-XL 是一个改进版的 Transformer,它引入了 相对位置编码 和 记忆机制,以帮助模型更好地捕捉长序列中的长期依赖关系。Conformer 采用了 Transformer-XL 中的相对位置编码技术,以提升在处理变长语音数据时的表现。 #### 4. 预归一化残差单元(Pre-norm Residual Units)
预归一化残差单元 是一种在深层网络中常见的技术,它将归一化层(如 LayerNorm)应用于每个残差连接的输入,而不是输出。
这有助于避免训练时梯度消失或爆炸的问题,特别是在非常深的网络中。此外,预归一化结构还可以加速模型的训练过程。
Dropout 技术用于防止过拟合,通过随机丢弃网络中的部分连接,增强模型的泛化能力。
5. 模型更深的训练和正则化
- 由于采用了预归一化残差单元和 Dropout,Conformer 模型能够更有效地训练更深的网络,并且减少过拟合的风险。
- 在复杂的任务(如语音识别)中,使用更深的网络通常能够捕获更丰富的特征表示,而上述技术帮助稳定训练过程。 ### Convolution layer

- 点卷积(Pointwise Convolution):
- 这是一个
卷积,用于通过 扩展因子(expansion factor)2 来增加通道数。这意味着输入的特征图经过该层处理后,输出的通道数是输入通道数的两倍。 - 点卷积后接 GLU(Gated Linear Unit) 激活函数,它通过门控机制来控制信息的流动,使得卷积的输出在学习过程中能够选择性地传递有用的特征。
- 这是一个
- 1-D 深度卷积(1-D Depthwise Convolution):
- 接下来是一个 1-D 深度卷积,这是对每个通道单独进行卷积操作,而不是跨通道共享卷积核。这种操作方式有助于降低模型的参数数量和计算量,同时能够捕捉输入数据中的局部特征。
- 批归一化(BatchNorm):
- 卷积操作后,加入 批归一化 层,这有助于标准化每一层的输出,减少梯度消失和爆炸问题,并加速模型训练。
- Swish 激活函数:
- 最后,经过 批归一化 后,使用 Swish 激活函数(Swish activation layer)。Swish 是一种自激活函数,具有类似于 ReLU 的特性,但在负数区域也有输出,使得网络在学习时能够更加平滑地收敛。 ### Feed Forward layer

- 最后,经过 批归一化 后,使用 Swish 激活函数(Swish activation layer)。Swish 是一种自激活函数,具有类似于 ReLU 的特性,但在负数区域也有输出,使得网络在学习时能够更加平滑地收敛。 ### Feed Forward layer
- 第一层线性变换(First Linear Layer):
- 使用一个 扩展因子(Expansion Factor) 为 4,将输入的维度扩展到更高的维度。这意味着输入的特征维度会增加 4 倍,以便提供更大的表示能力。
- 第二层线性变换(Second Linear Layer):
- 经过扩展后的特征在第二层线性变换中被 投影回模型维度(Model Dimension),恢复到与输入相同的维度。
- Swish 激活函数(Swish Activation):
- 在两个线性变换之间应用 Swish 激活函数,提供非线性变换。Swish 激活函数有助于更平滑的梯度传播,避免了 ReLU 激活函数可能引起的死神经元问题。
- Pre-Norm 残差单元(Pre-Norm Residual Units):
- 采用 Pre-Norm 的残差结构,即在每个残差连接之前先进行 层归一化(Layer Normalization),以增强模型训练的稳定性和效率。
Conformer Block 结构
- Conformer Block 采用了一个 三明治结构(Sandwich Structure),其顺序为:两个 前馈模块(Feed Forward Modules),中间夹着 多头自注意力模块(Multi-Headed Self-Attention, MHSA) 和 卷积模块(Convolution Module)。
- 这个结构的灵感来自于 Macaron-Net,它提出用 两层半步前馈层(Half-Step Feed-Forward Layers) 来替代 Transformer 中的传统前馈层。
- 半步前馈层:在 Macaron-Net 中,原本的一个前馈层被分解为两个半步前馈层:一个在 自注意力层之前,一个在 自注意力层之后。这样做的目的是更好地平衡信息的传递,增强信息流动。因此两个前馈层的输出都乘以二分之一
- 该块的计算过程可以用下面的公式表示: