本文介绍transformer。
transormer主要解决了seq2seq的问题,由模型自己决定输出的长度 ## Seq2Seq
主体架构
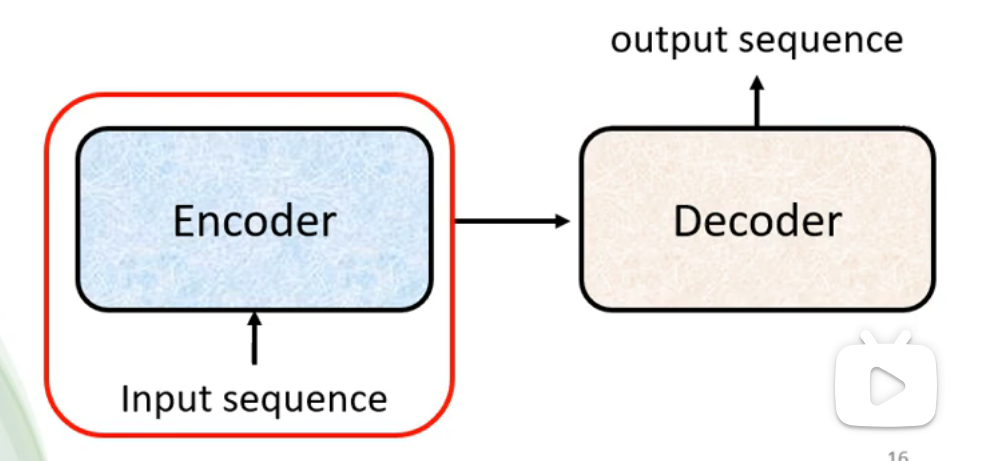
Encoder
- 功能:将输入的向量转化为另一组向量。
- Transformer中的Encoder结构:
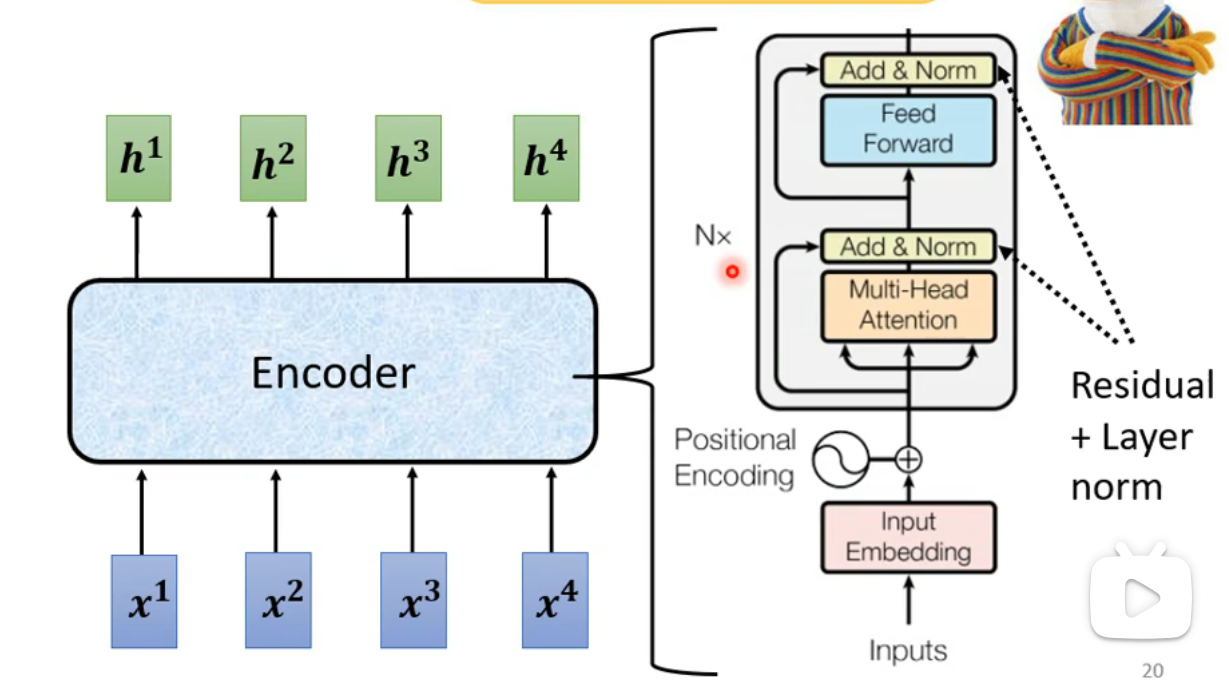
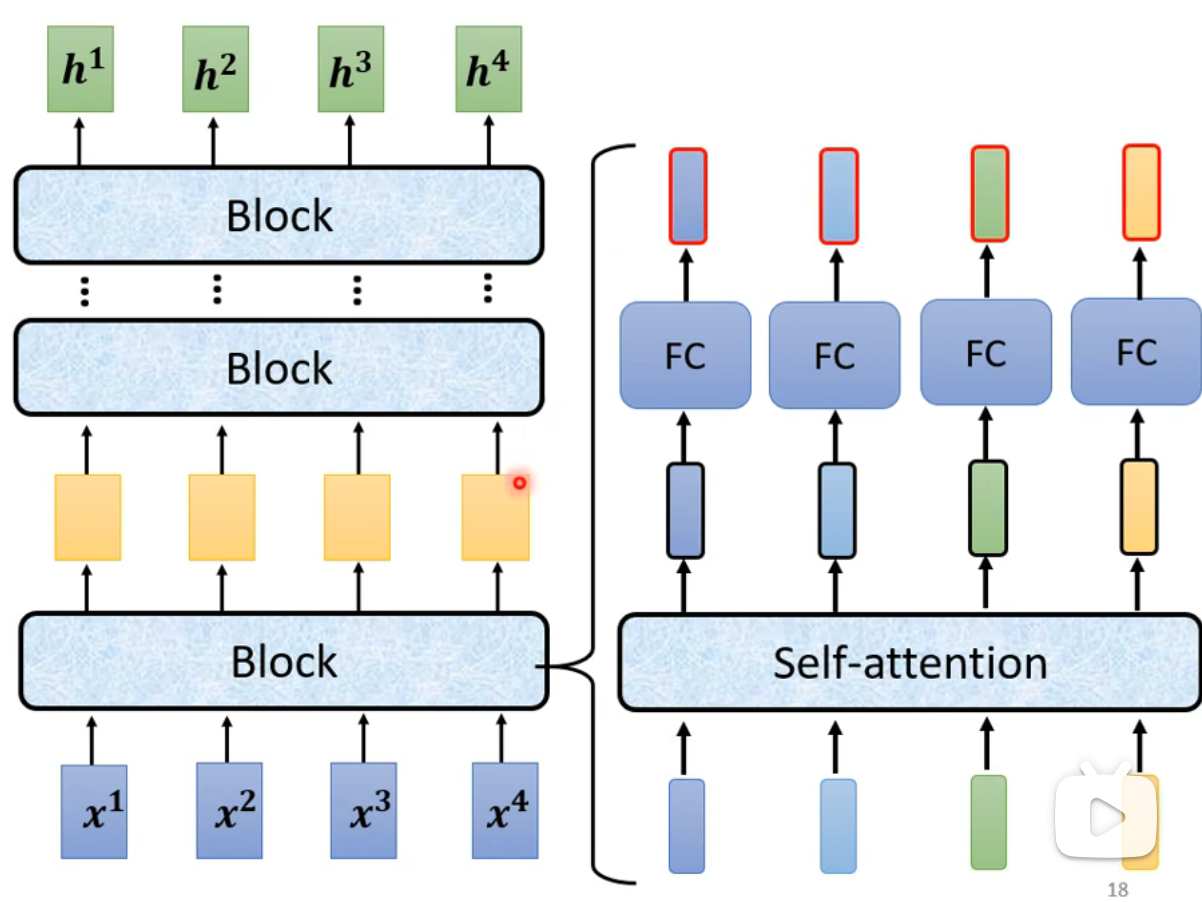
- Encoder由多个block组成。在Transformer中,每个block采用的是Self-Attention机制:
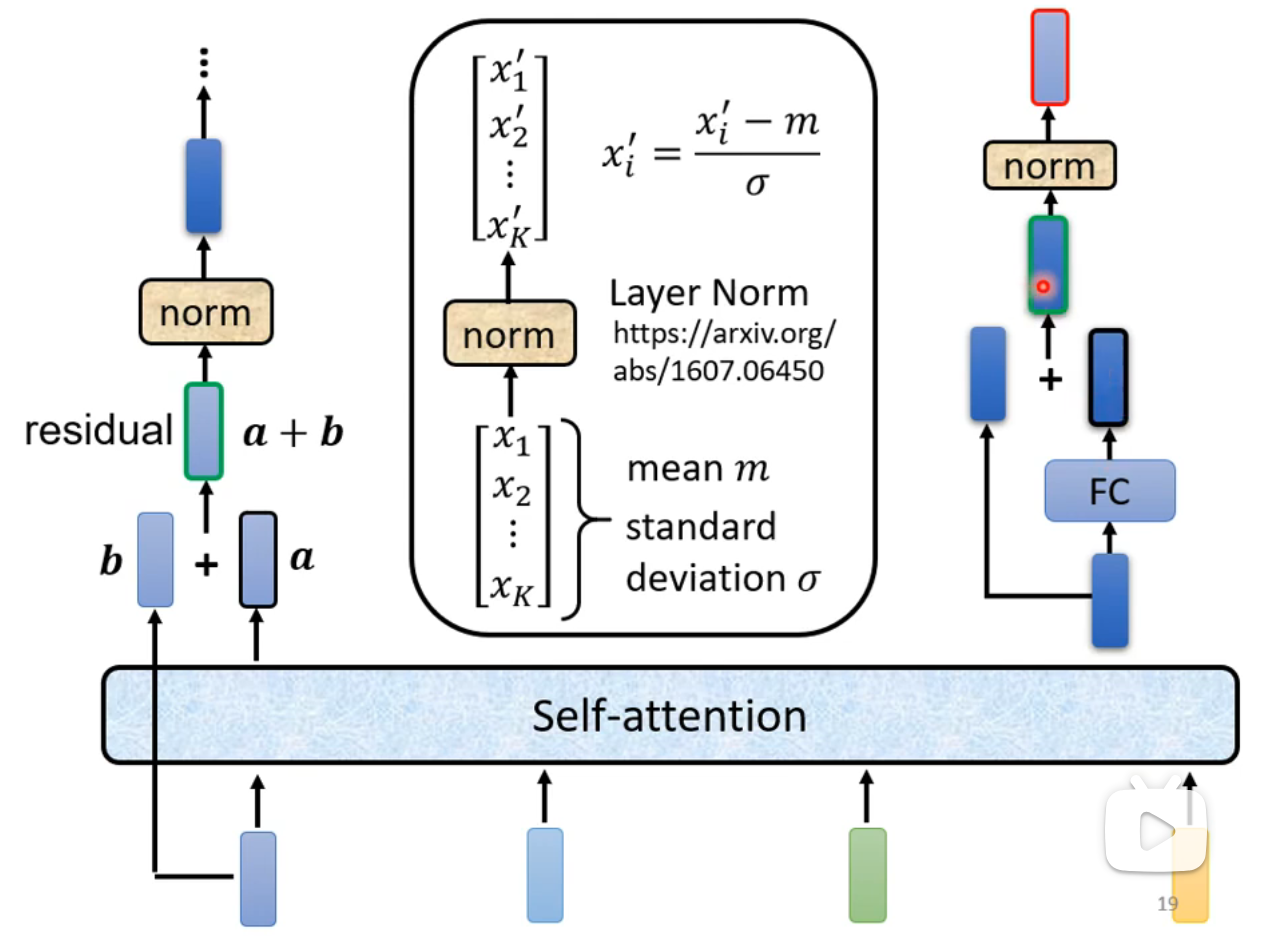
- Transformer对Self-Attention得到的向量进行残差连接(Residual Connection)后,再进行一次层归一化(Layer Normalization),然后作为全连接层(FC)的输入。全连接层同样会进行残差连接和层归一化:
Decoder
Autoregressive Model
- 输出分布:字符集,表示目标数据集合。例如中文中的每个汉字,英文中每个字母或单词。输出应包含一个终止符号
$END$,一旦输出该符号,Decoder的过程即告结束。 - Decoder通过Softmax计算输出概率,并选择概率最高的字符作为当前输出。
- 新的输出会作为下一步输入,继续解码过程。
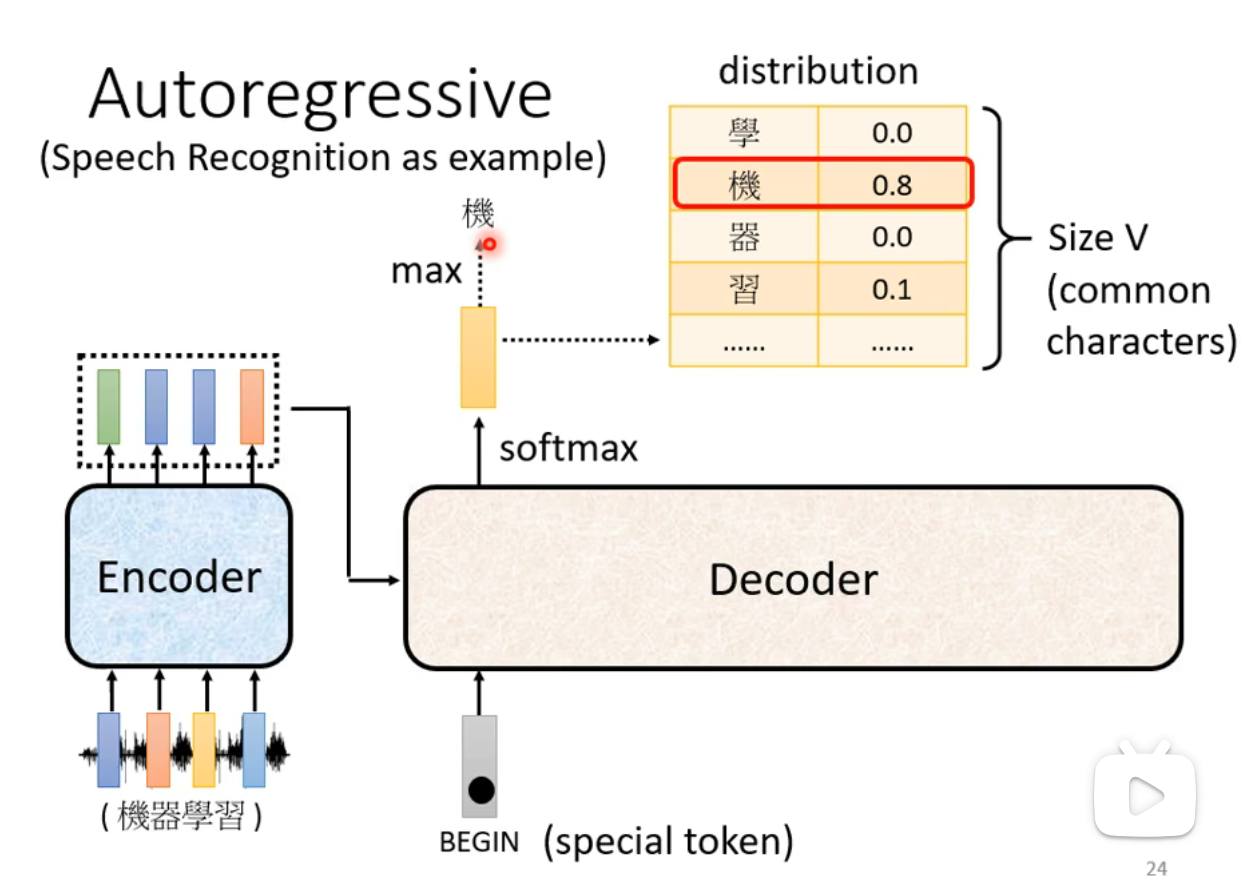
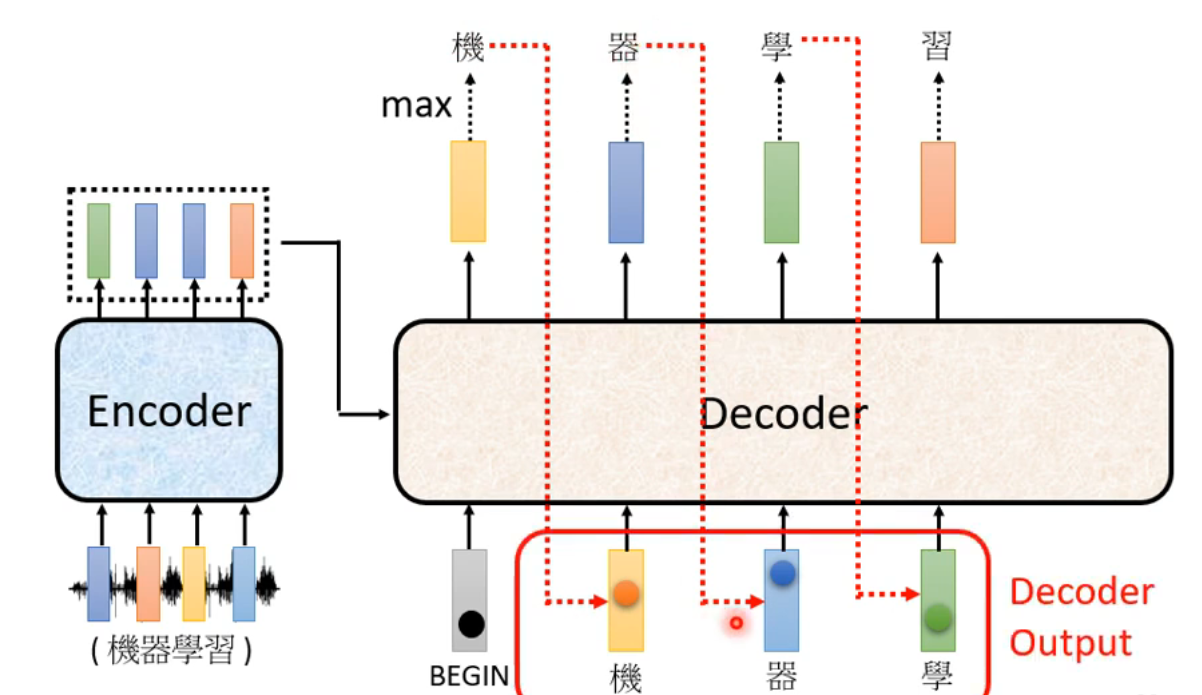
Autoregressive Decoder架构
与Encoder相比,Decoder主要多了一个Masked Self-Attention模块: 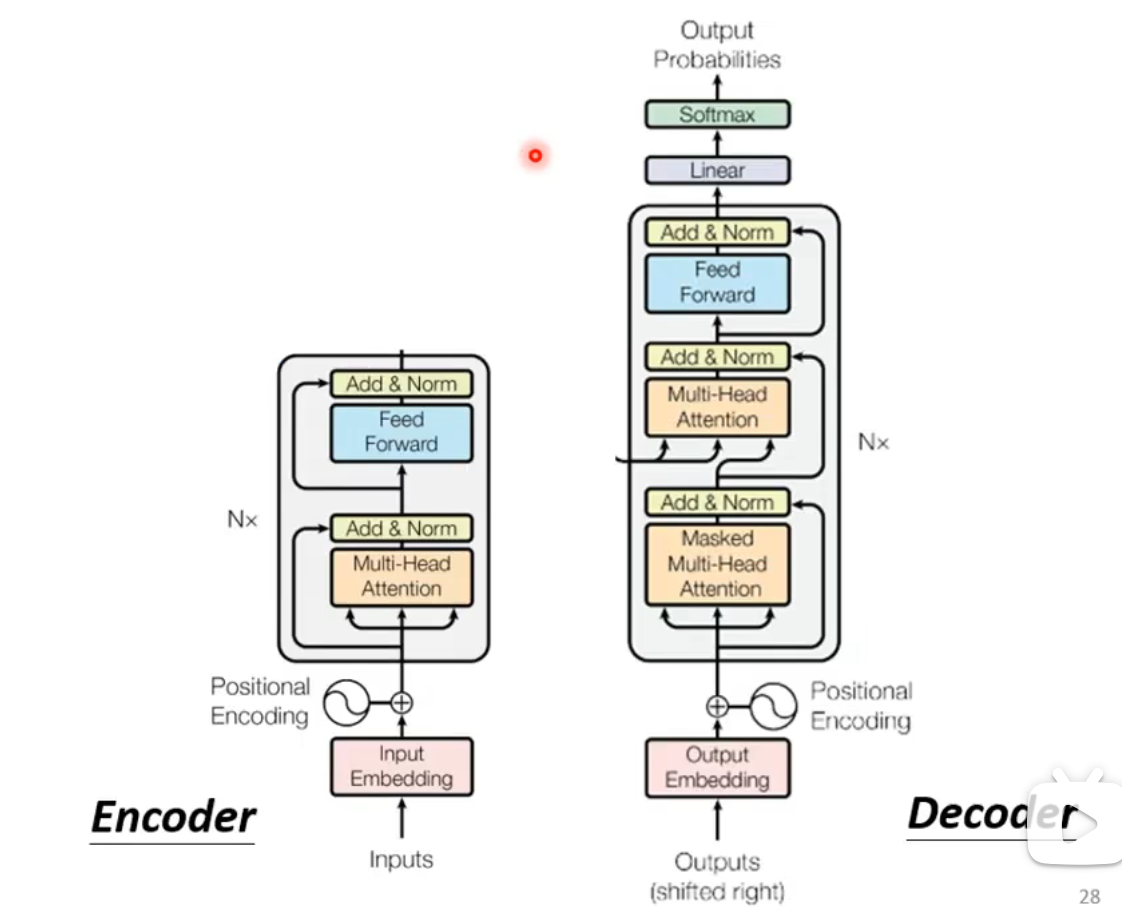 - Masked Self-Attention:在生成输出
- Masked Self-Attention:在生成输出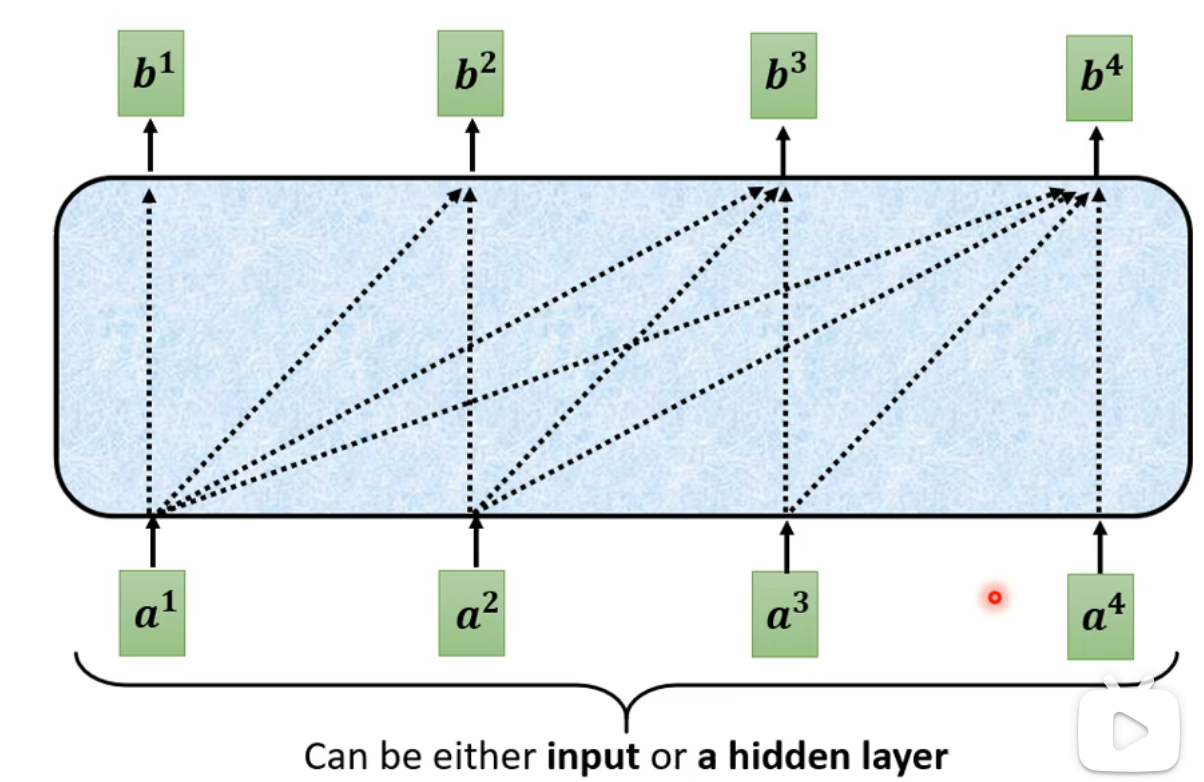
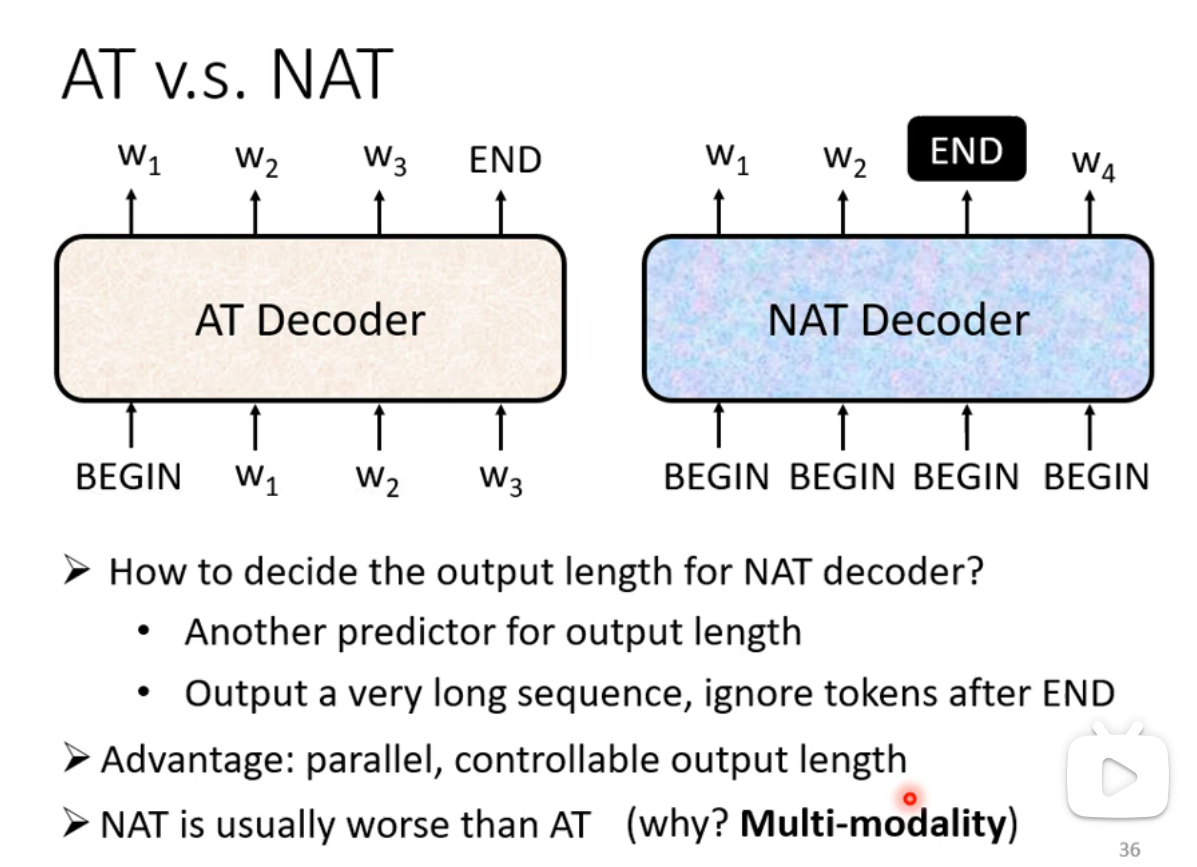
Non-autoregressive Decoder(NAT)
- Autoregressive vs Non-autoregressive
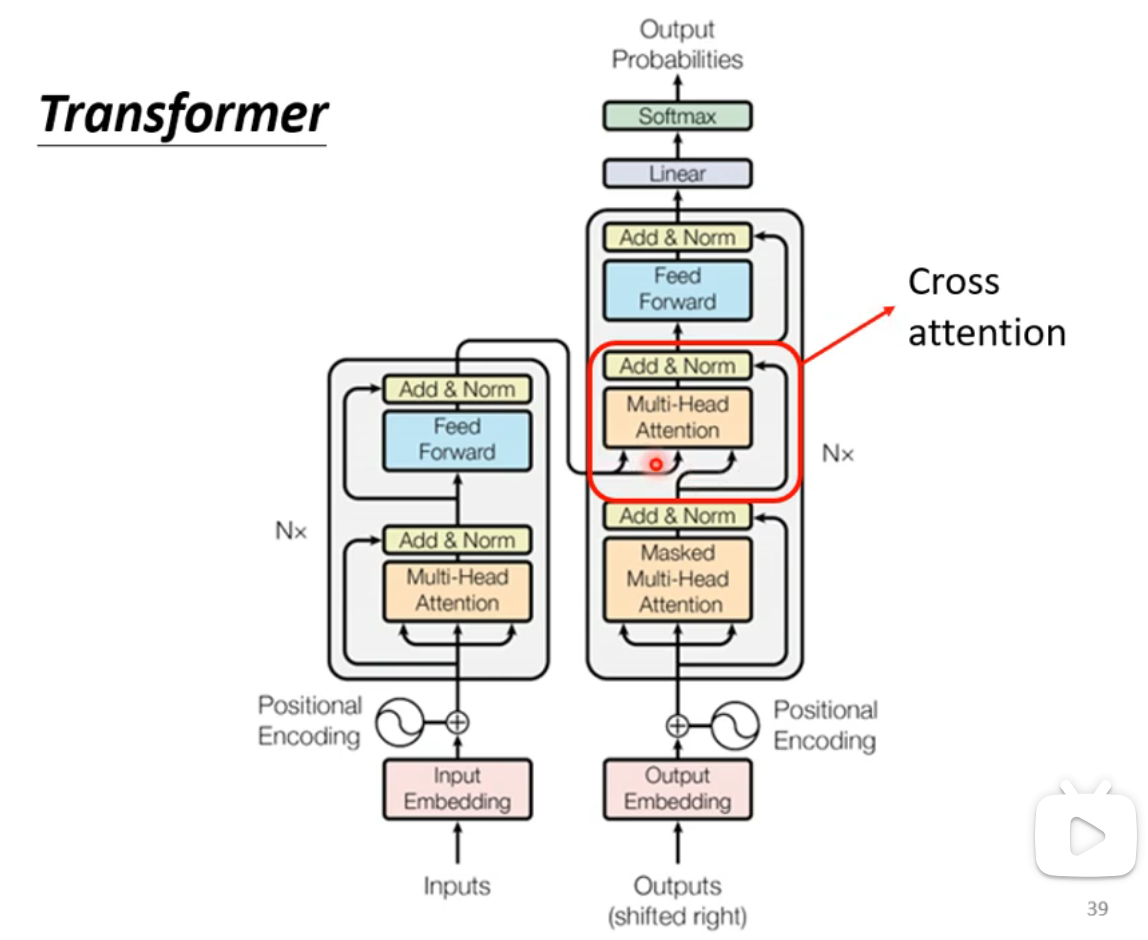
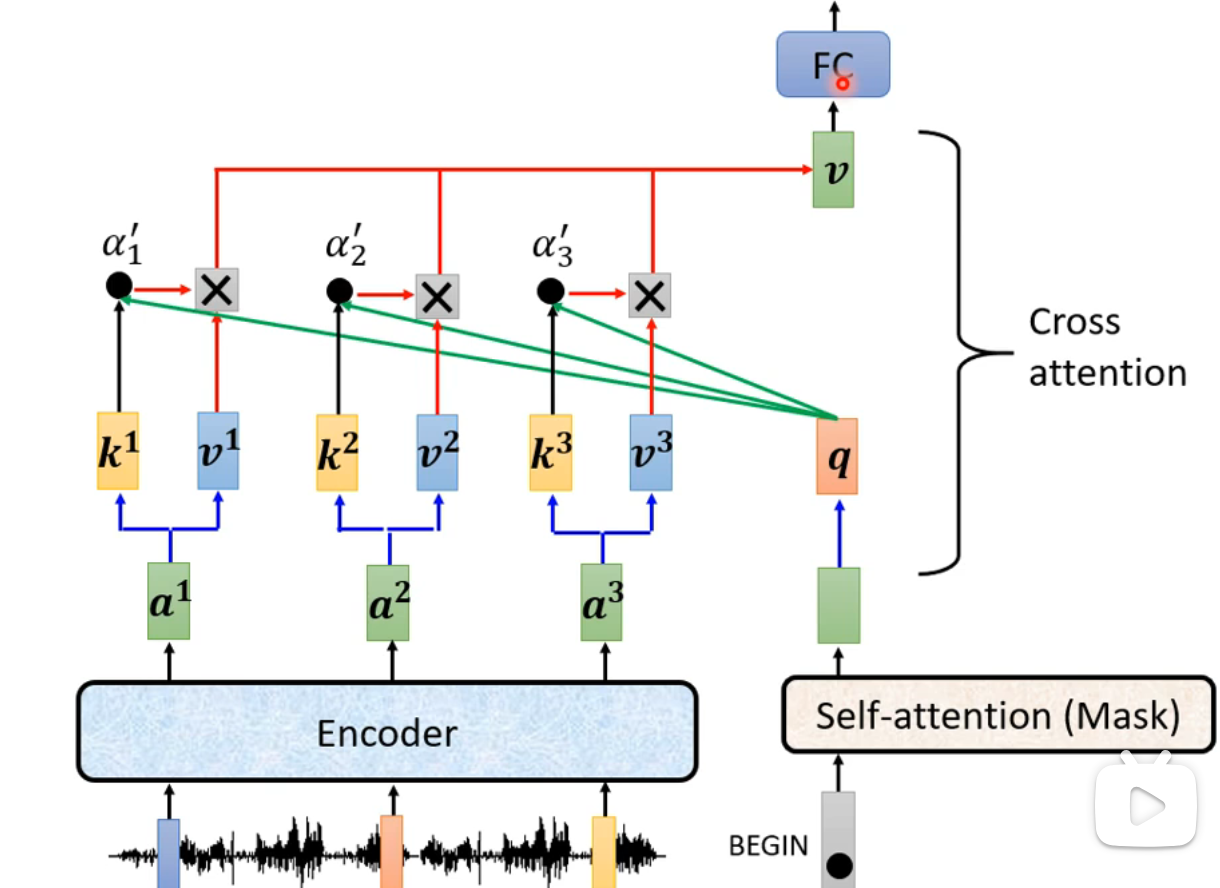
Encoder与Decoder的交互(Cross Attention)
- Encoder具有两个输入箭头,Decoder只有一个输入箭头:
- 工作流程:
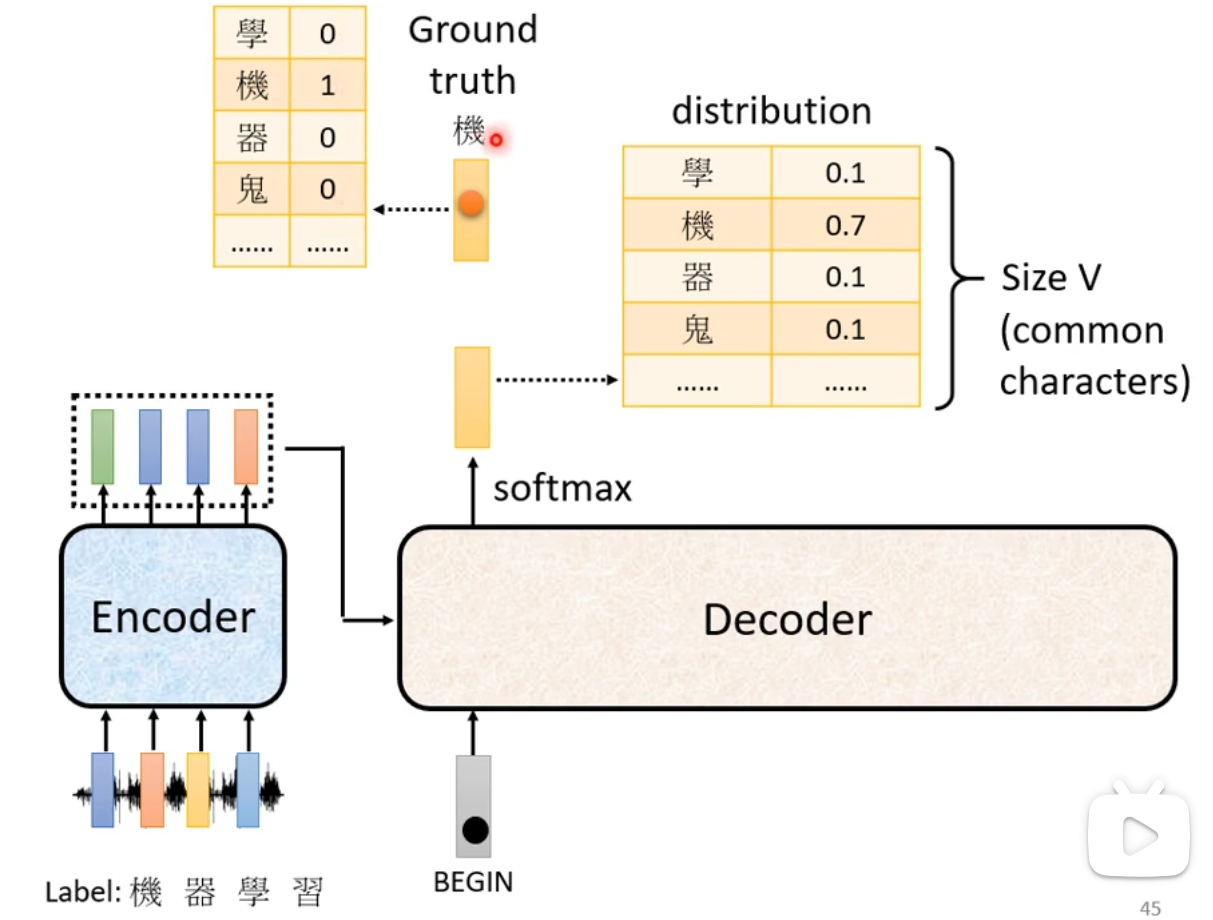
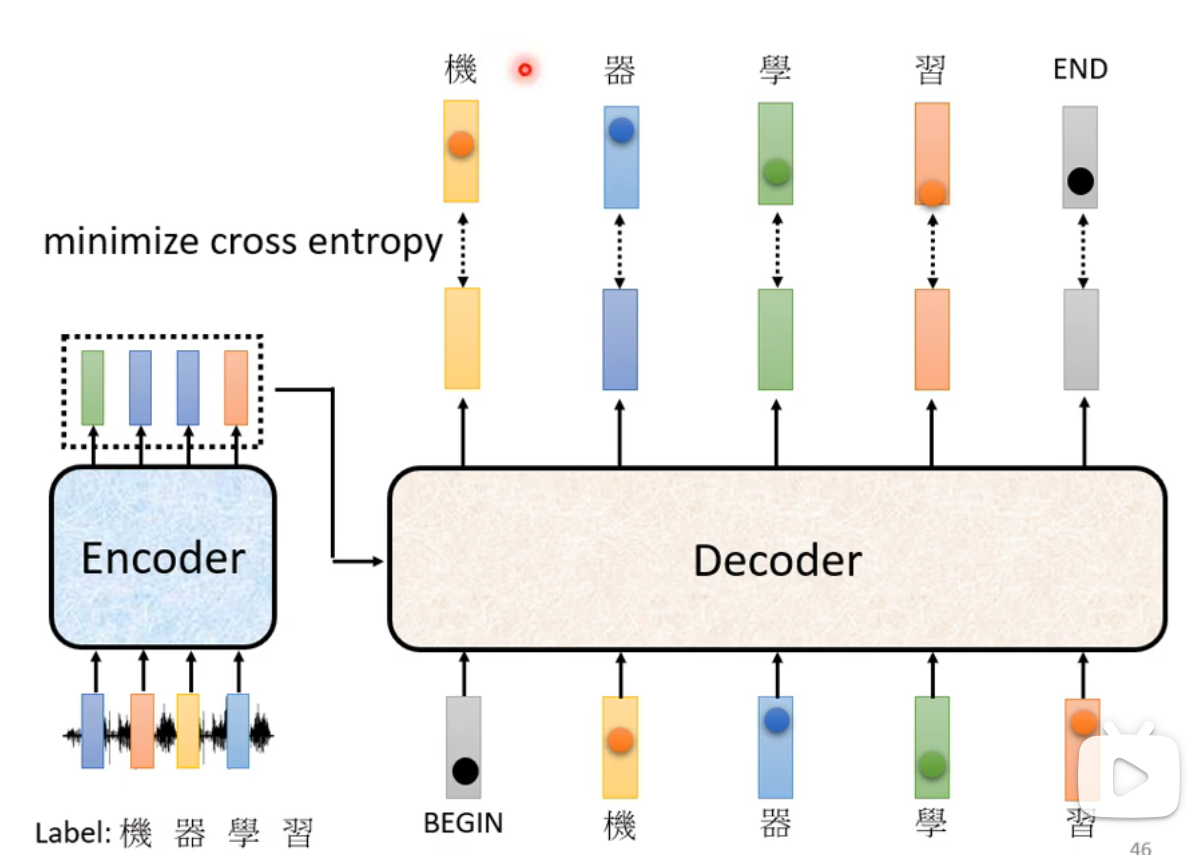
如何训练
- Ground Truth:使用One-hot编码标注数据,并通过交叉熵(Cross-Entropy)将Decoder的输出与Ground Truth进行对比。
- 每一个输入产生的输出都会计算交叉熵,最终目标是最小化所有输出的交叉熵之和。
- 训练时,Decoder的输入是Ground Truth(即Teacher Forcing)。
训练技巧
Copy Mechanism
- 直接从输入中复制部分内容到输出中,尤其对于长文本生成任务有助于提升模型的表现。
Guided Attention
- 引导模型的注意力机制,按照某些规则或模式进行聚焦。
- 例如在语音合成任务中,模型通常按顺序从左到右分析语音信号。
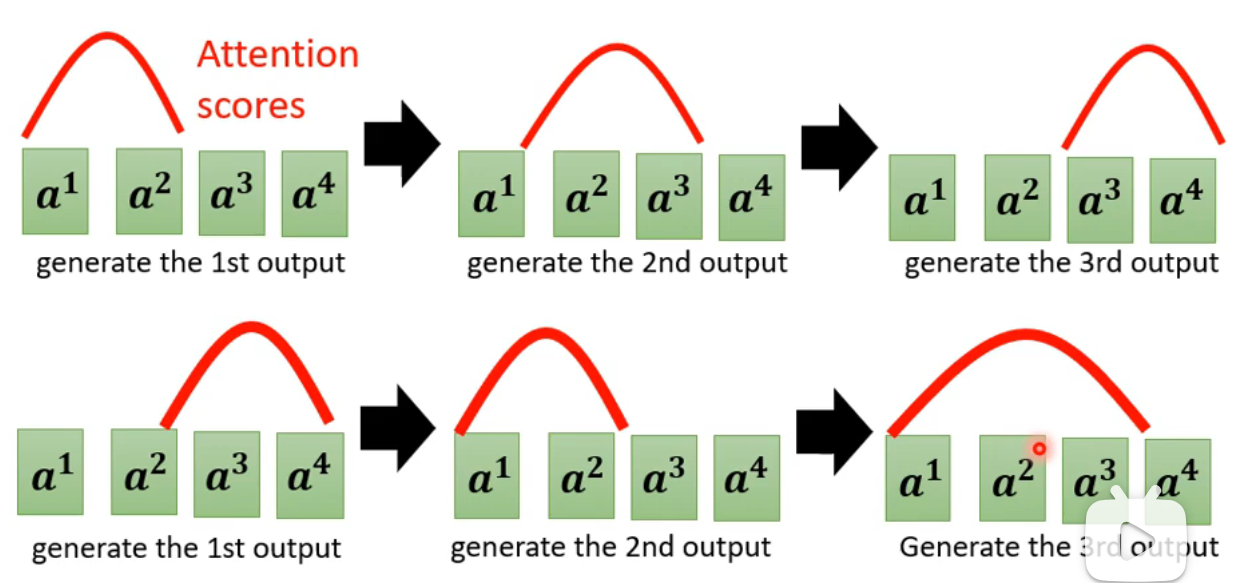
- 例如在语音合成任务中,模型通常按顺序从左到右分析语音信号。
Beam Search
- Beam Search是一种启发式搜索算法,用于在解码阶段生成多个候选序列,并选择最优的解码路径。
Scheduled Sampling
- Scheduled Sampling是一种训练策略,通过逐步减少训练阶段中使用Ground Truth的比例,鼓励模型在生成过程中逐渐依赖于自己预测的结果,而非Ground Truth。