本笔记统一整理李宏毅深度学习课程中"what to do if my networks fail to train"的内容 ## 特征归一化(Feature Normalization)
在训练神经网络时,我们希望误差曲面(error surface)尽量规整,这样在不同可学习参数下的误差变化趋于一致。如果在不同方向上误差曲面变化不均匀,训练过程就需要不同的学习率来匹配每个方向。例如在下图中,
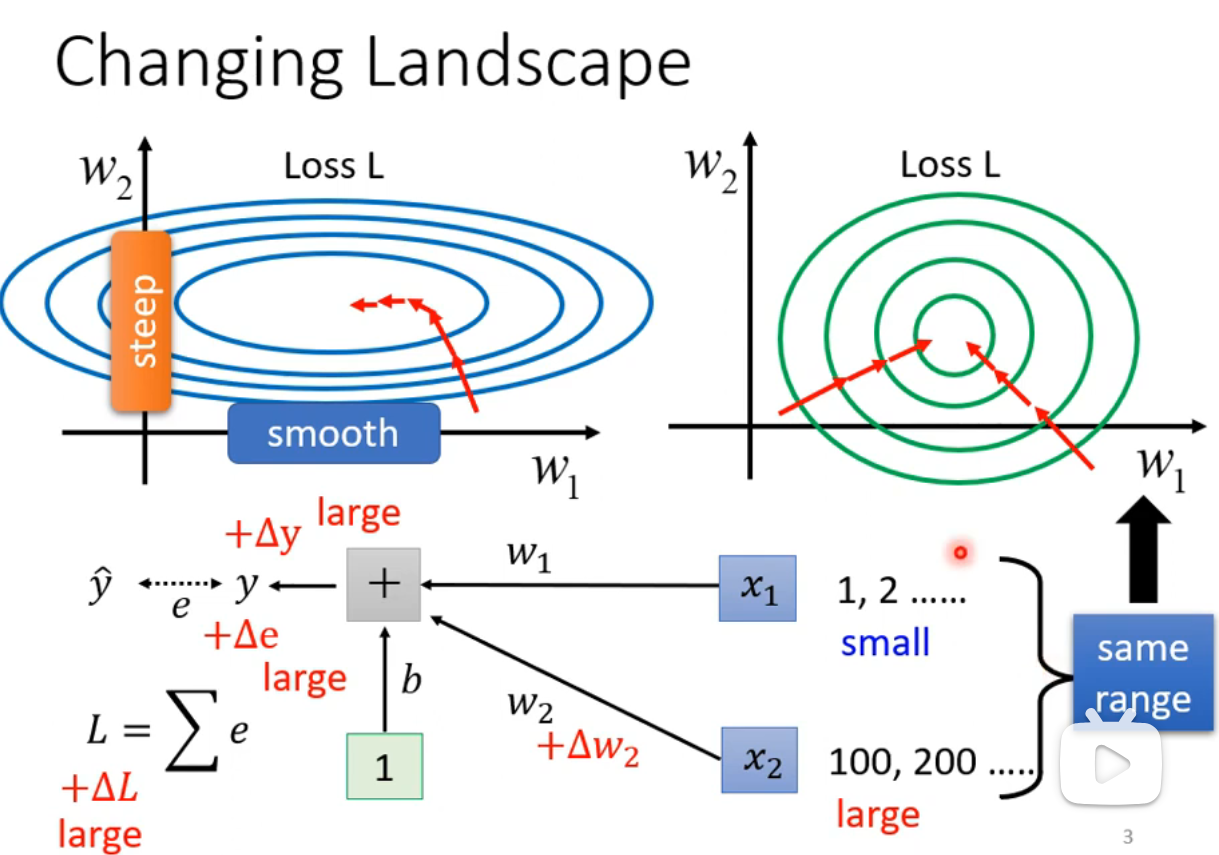
然而,除了调整学习率,还可以直接改变误差曲面的形状,通过对输入特征进行归一化,让各个方向上的变化更加一致。这种方法能使得模型的各个方向上对误差的敏感性相似,进而加快收敛速度。
特征归一化的方法
一种常用的特征归一化方法是标准化(Standardization),即让每个特征维度的均值为 0,方差为 1,使其类似于标准正态分布:
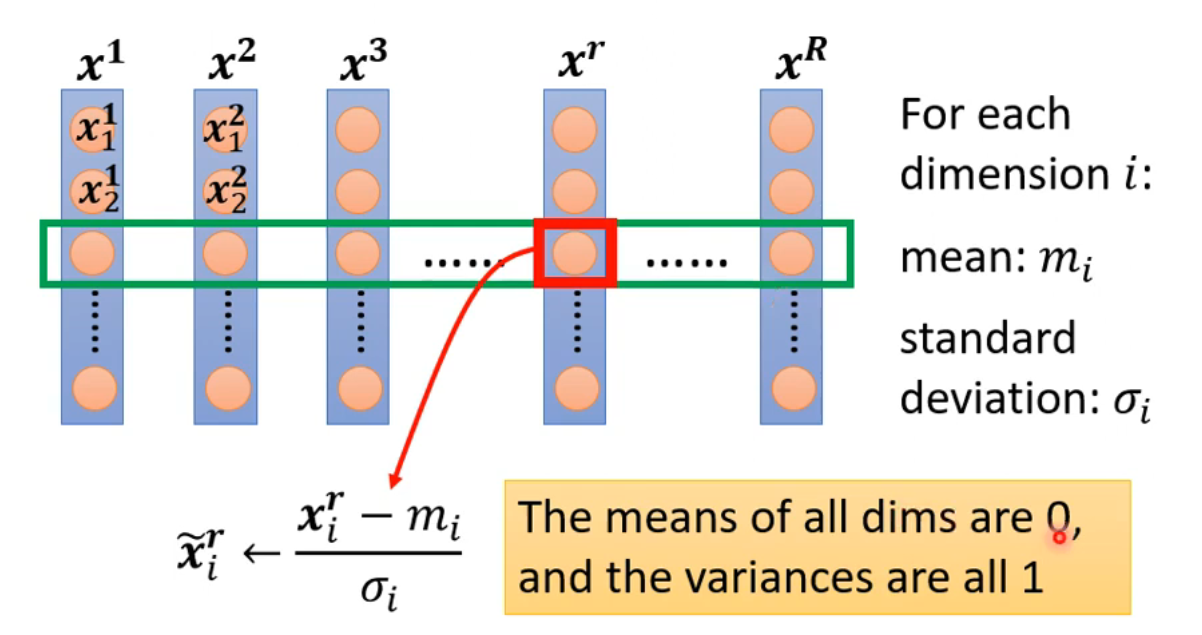
注:激活函数前后的归一化效果差异通常不大。
批归一化(Batch Normalization)训练阶段
在计算所有样本的均值
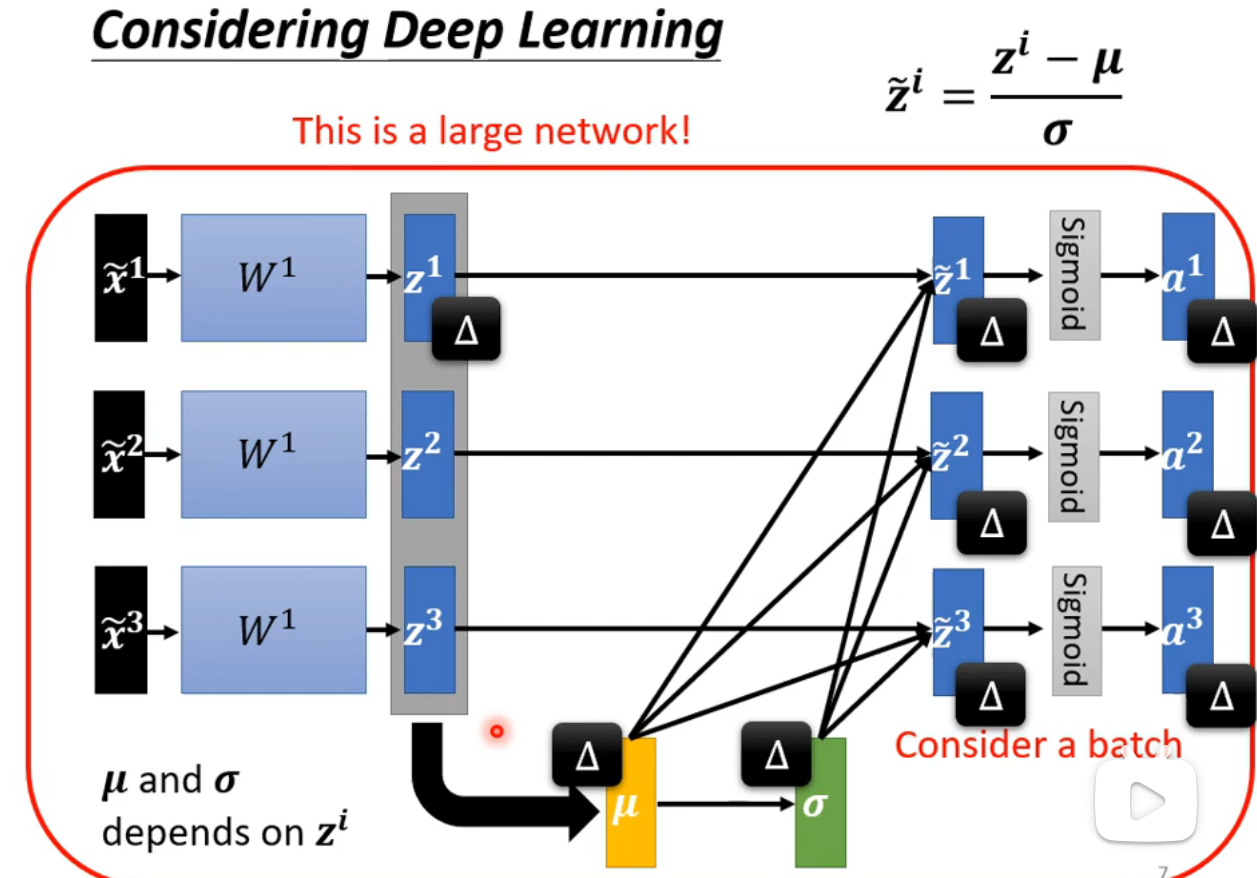
通常批归一化会引入两个可学习的参数
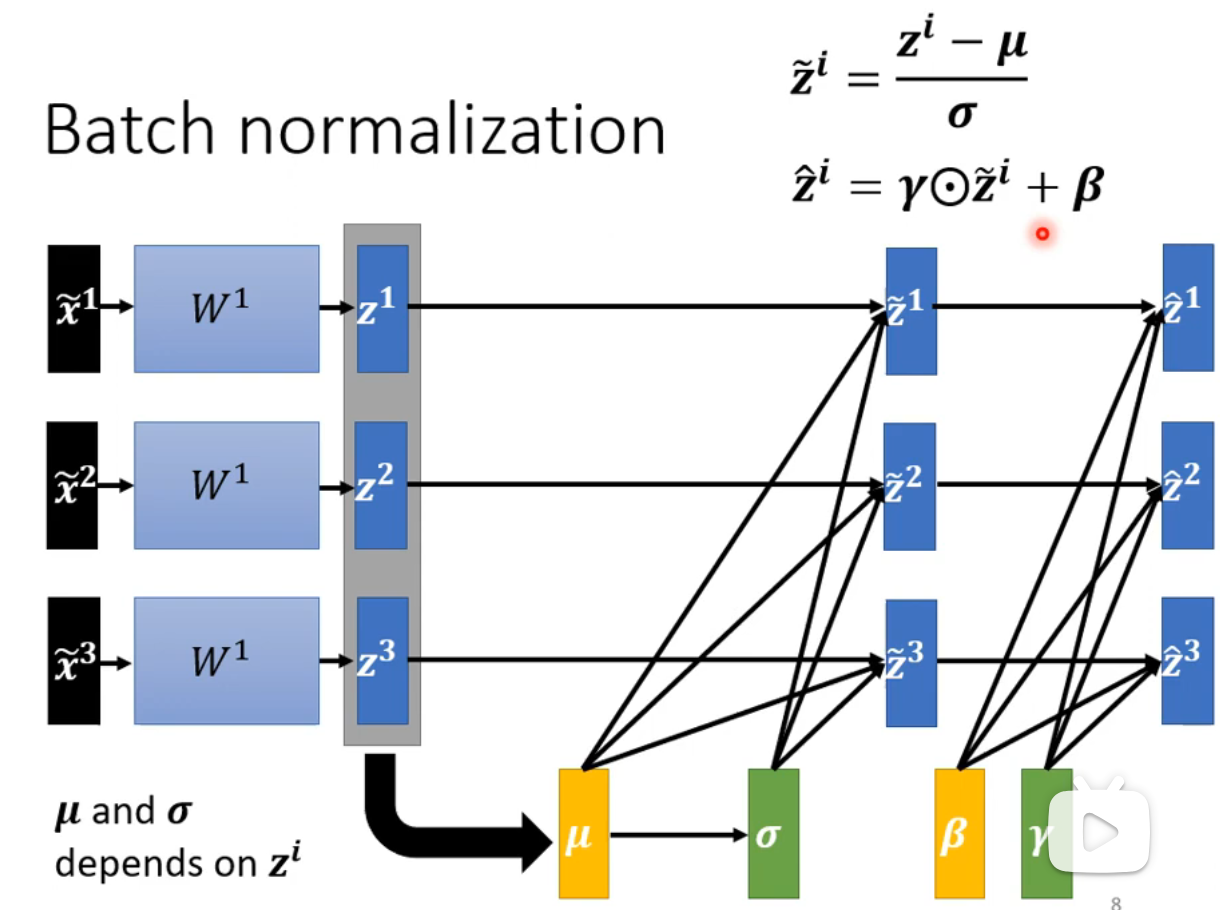
批归一化(Batch Normalization)测试阶段
在测试阶段,模型会使用训练过程中计算得到的移动平均值(moving average)来进行归一化处理,确保模型在训练和测试期间表现一致。
